
1. 개요
Amazon QuickSight는 Amazon Web Services에서 제공하는 클라우드 기반 BI 도구로, 데이터 시각화를 쉽게 할 수 있게 도와줍니다. QuickSight를 통해 데이터 소스와 연결해 대시보드, 리포트, 그래프 시각화 자료를 만들 수 있습니다.
S3 에 저장된 로그데이터를 Amazon Athena 를 통해 분석해 Quicksight 를 연결하여 시각화를 하거나 복잡한 AWS CUR 빌링데이터를 Amazon Athena 를 통해 분석하고, Quicksight 를 통해 시각화하여 간단한 방법으로 비용 분석이 가능하도록 하는 등 다양한 영역에서 활용 가능합니다.
본문의 간단한 Hands on 을 통해 AWS 서비스만을 이용하여 복잡한 데이터를 분석하고 시각화하는 과정에 대해 알아보겠습니다.
2. 본문
S3 에 적재한 데이터를 Amazon Athena 를 통해 분석하고, Amazon QuickSight 를 통해 시각화하는 간단한 Hands on 을 통해 데이터 시각화 과정을 알아보겠습니다.
1.S3 버킷 생성하고 , 특정 경로에 데이터 적재(table1/)
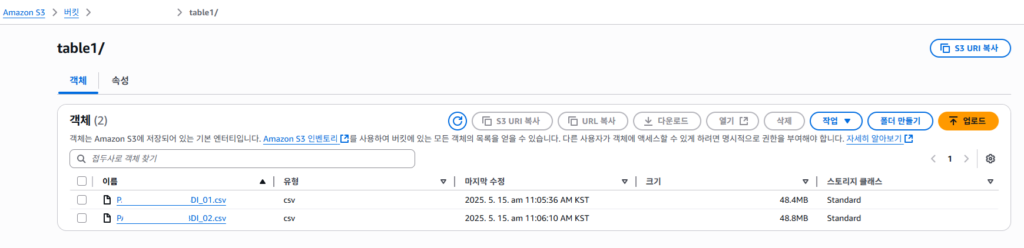
2.Athena 를 통해 Database, table 생성
1) Athena 작업 그룹 생성
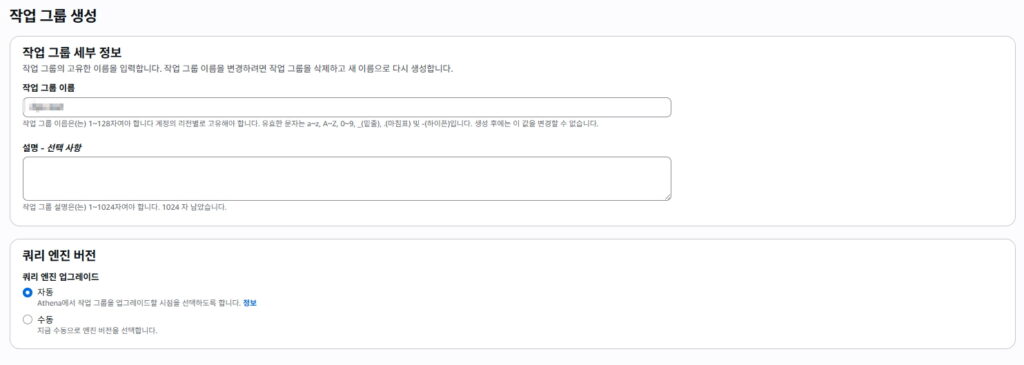
** Athena 사용시 기본으로 primary 라는 작업그룹이 생성되어있는데 그걸 사용해도 된다.
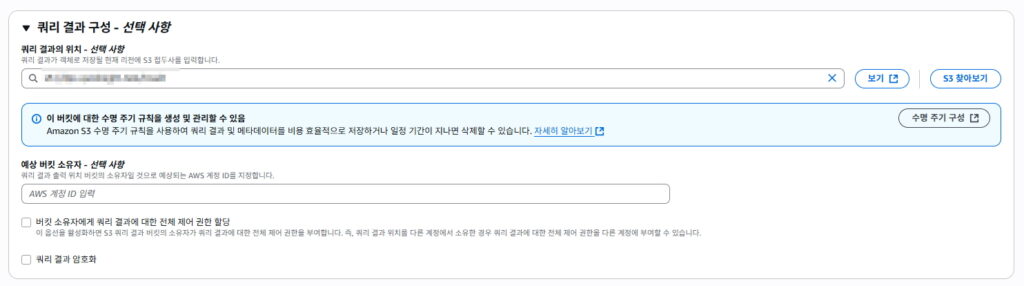
쿼리 결과를 저장하고 싶은 경로가 있다면 “쿼리 결과 구성”에서 쿼리 결과의 위치를 지정해준다.
2)Athena 쿼리 편집기에서 쿼리를 통해 데이터베이스 생성 – 테이블 만들기 전 데이터베이스가 필요함
CREATE DATABASE IF NOT EXISTS [데이터베이스명];
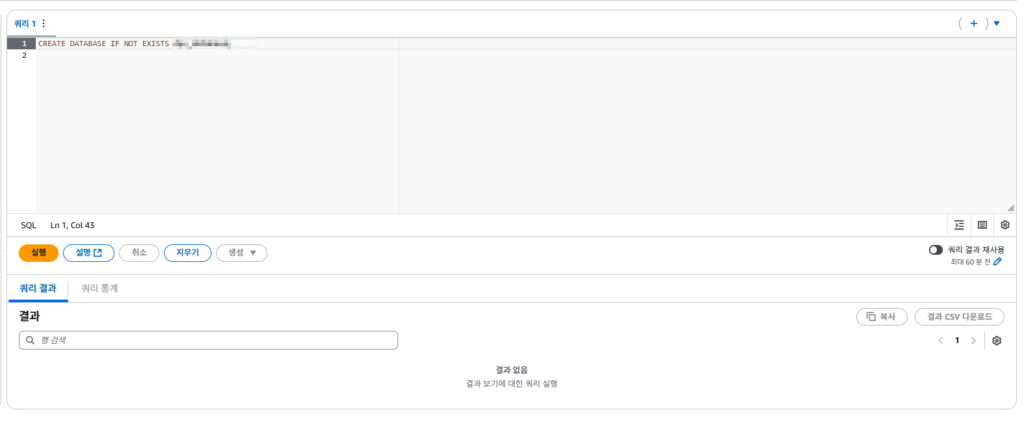
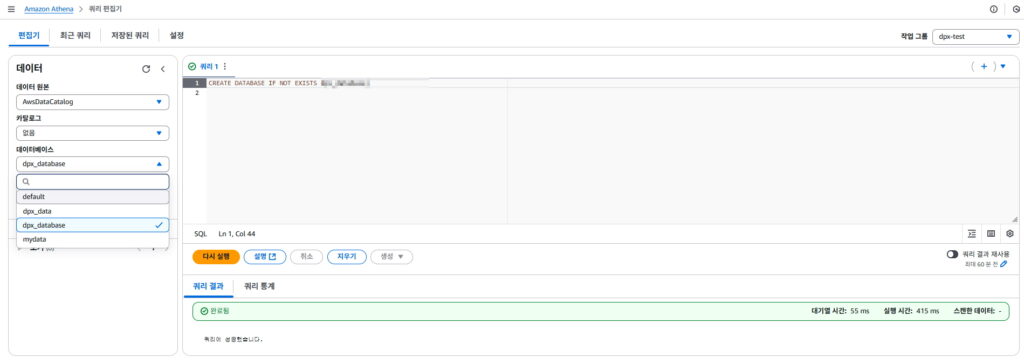
데이터베이스가 정상적으로 생성되면 데이터베이스에서 새롭게 생성한 데이터베이스를 선택 가능하다.
Athena에서 쿼리를 통해 생성한 Database 는 Glue Data Catalog 에도 자동으로 등록되며, Database 는 Glue Data Catalog 에서도 생성할 수 있다.

다시 Athena 로 돌아와
생성한 데이터베이스를 선택하고 테이블 및 보기에서 “생성” 을 선택하고 “S3 버킷 데이터” 를 선택한다
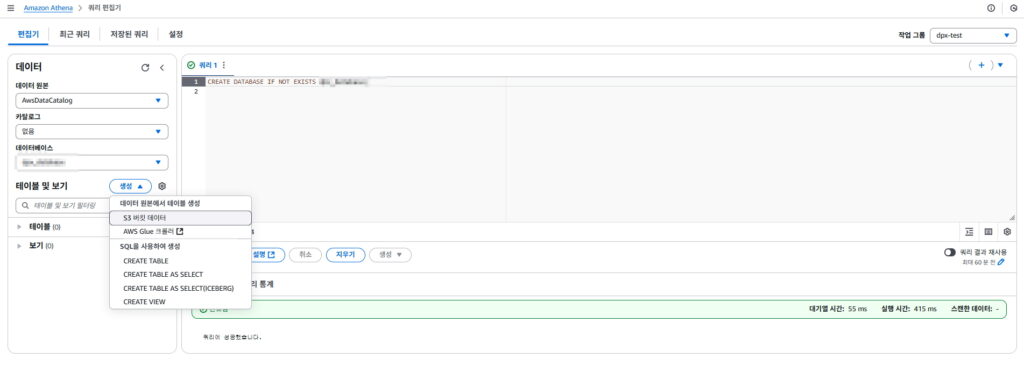
3)S3 버킷 데이터에서 테이블 생성
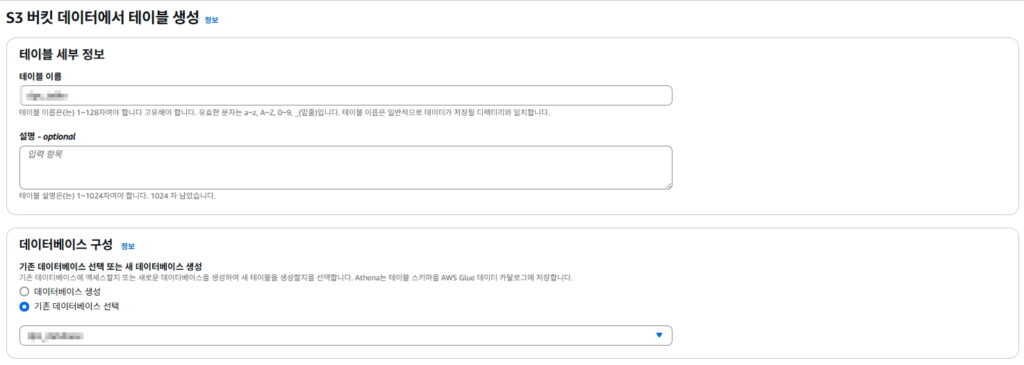
테이블 이름 지정
데이터베이스 구성은 앞서 생성한 데이터베이스 선택
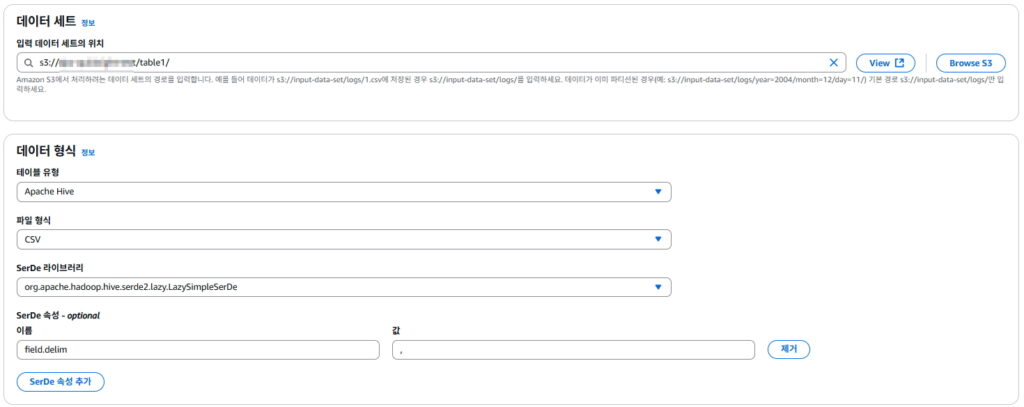
데이터 세트 경로는 분석할 csv 가 저장된 S3 경로 선택
데이터 형식
-테이블 유형 : Apache Hive (default, 표준 Athena 테이블 타입)
-파일 형식 : CSV (S3 데이터베이스 형식이 csv)
-SerDe 라이브러리 : org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe (default, CSV, TSV 등 간단한 텍스트 포맷을 파싱할 때 사용하는 기본 SerDe)
-SerDe 속성 : field.delim = , (default, 쉼표 구분자 csv)
열 세부 정보에 빌링데이터 Column name 과 Data type 을 입력해준다.
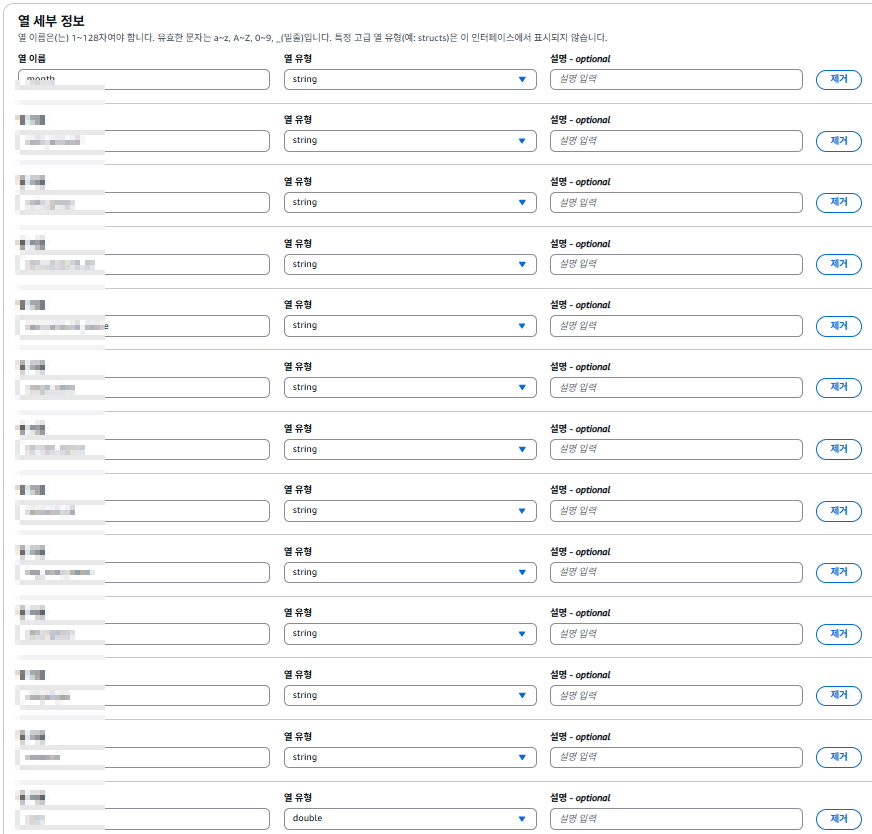
-string : 일반적인 문자열
-double : 소수점 포함하여 계산하기 용이
테이블 생성 완료하면
Athena에서 테이블이 확인되고
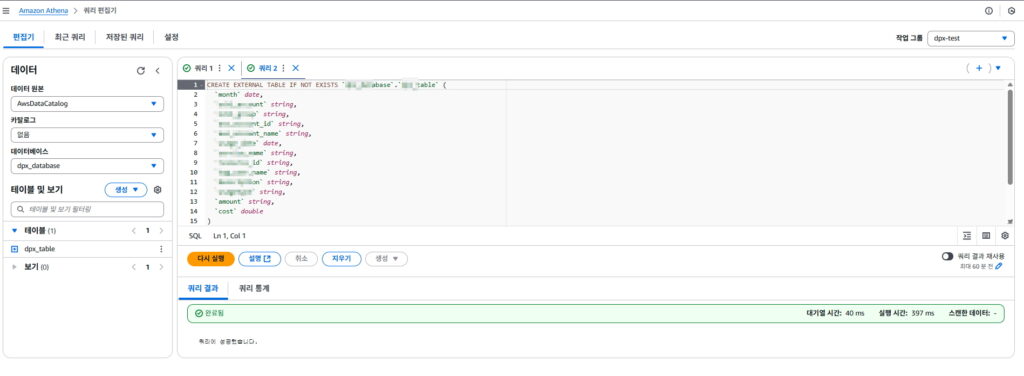
Glue Data Catalog 에도 테이블이 자동 등록된 것을 확인할 수 있다.

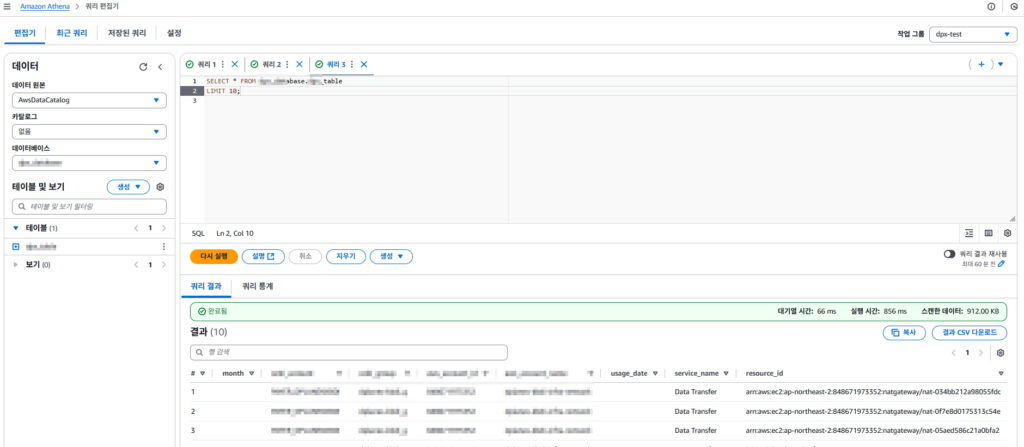
간단한 쿼리 실행 결과 테이블 잘 등록되었는지 확인 가능
3.Amazon Quicksight 를 통한 데이터 시각화
Amazon Quicksight 는 시각화 tool로, 최종 사용자에게 데이터를 보이게 해주는 역할을 함.
Athena에서 쿼리 결과를 불러와서 데이터를 차트, 그래프, 대시보드 등으로 보여주도록 설정한다.
1)퀵사이트 가입하기
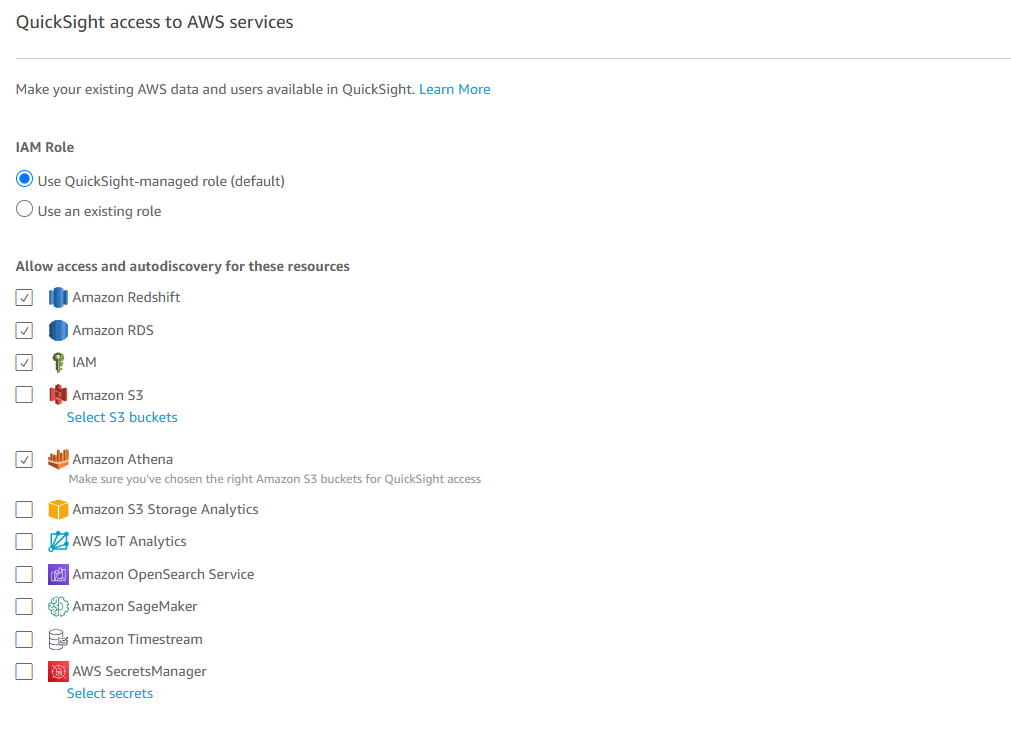
Quicksight에 부여해야 하는 리소스 접근 권한을 선택해주고,
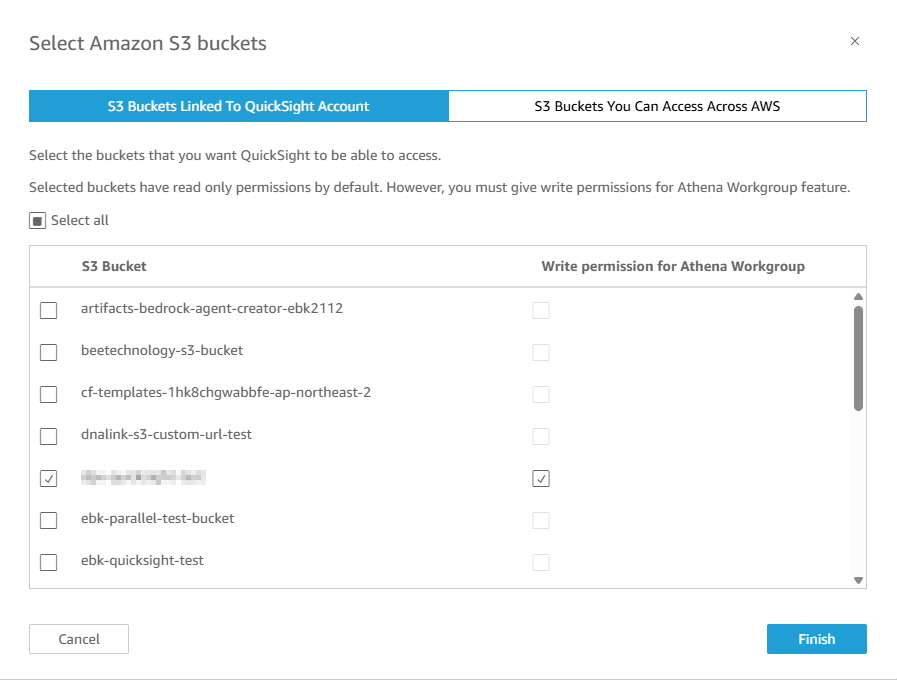
데이터를 저장한 S3 에 접근할 수 있는 권한과, Athena 쿼리 결과를 해당 버킷에 저장할 수 있는 권한인 “Write permission for Athena Workgroup” 을 선택한다.
가입이 완료되면 Quicksight 를 통해 데이터를 시각화 가능하다.
2)NEW DATASET 선택
FROM NEW DATA SOURCES – Athena 선택
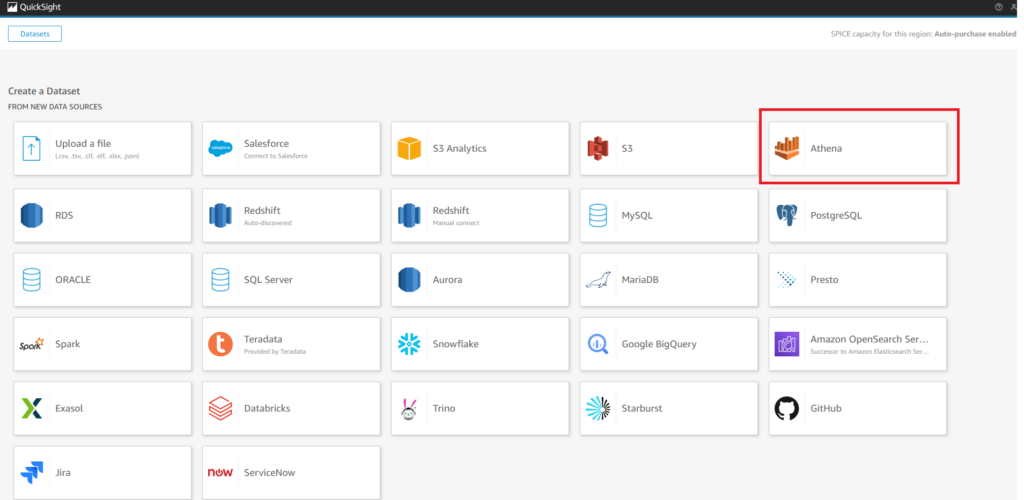
Data source name 지정하고, Athena workgroup 선택해주고 “Validate connection”
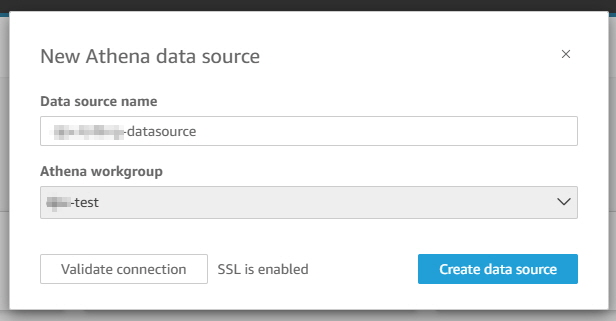
Validated 확인하면 “Create data source”
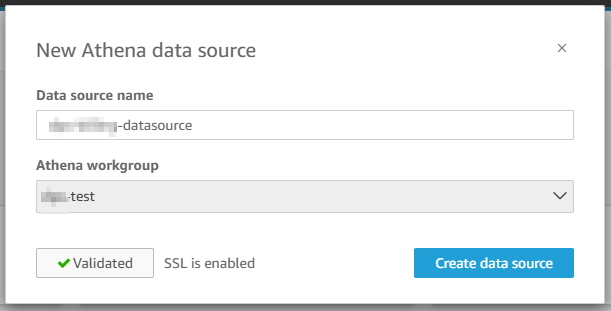
Database 와 Tables 선택하고 “Select”
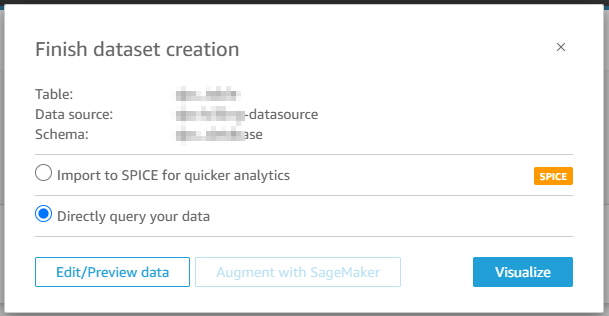
쿼리 날리는 방식 선택
-Import to SPICE for quicker analystics : 데이터를 SPICE 에 가져와서 캐시함
-Direct query your data : 매번 실시간으로 Athena 에 직접 쿼리 날림
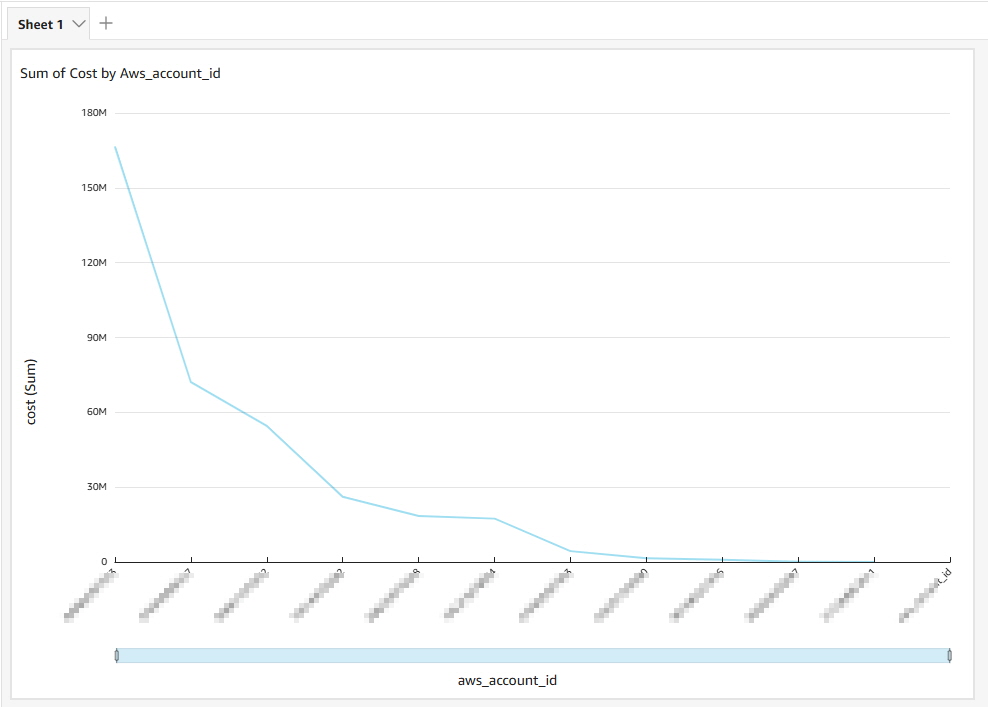
“Visualize” 후 그래프 생성 등 원하는 시각화 가능
-Ex ) 계정별 cost 조회
쿼리 결과도 workgoup 생성시 지정한 경로에 잘 쌓이고 있음
4.추가 case 테스트
1)테이블 스키마를 변경하는 경우
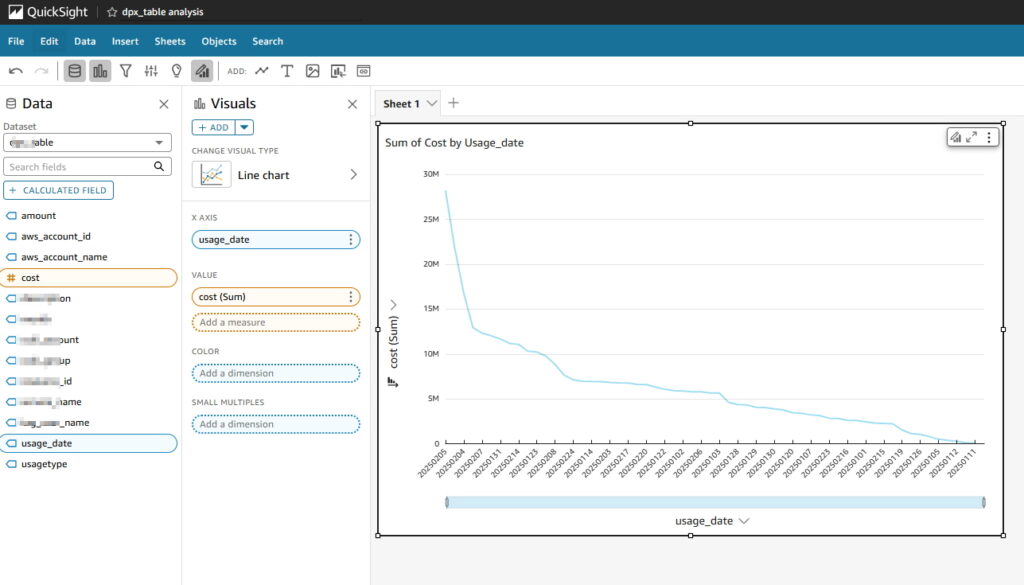
시각화 시 데이터를 잘 불러오지 못한다면 테이블의 스키마를 변경해야 하는 경우가 발생할 수 있다.
사용 일자로 조회했더니 조회 잘 안됨
Glue Data Catalog > tables > 해당 테이블 선택 > Edit schema
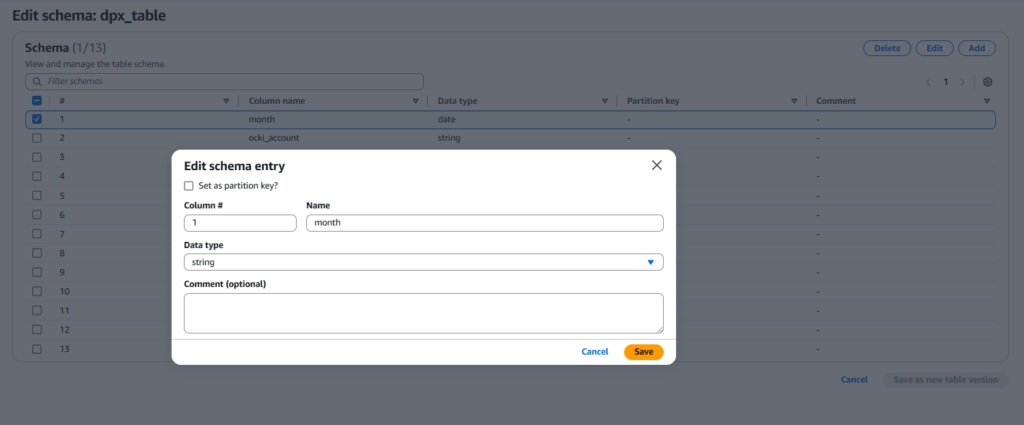
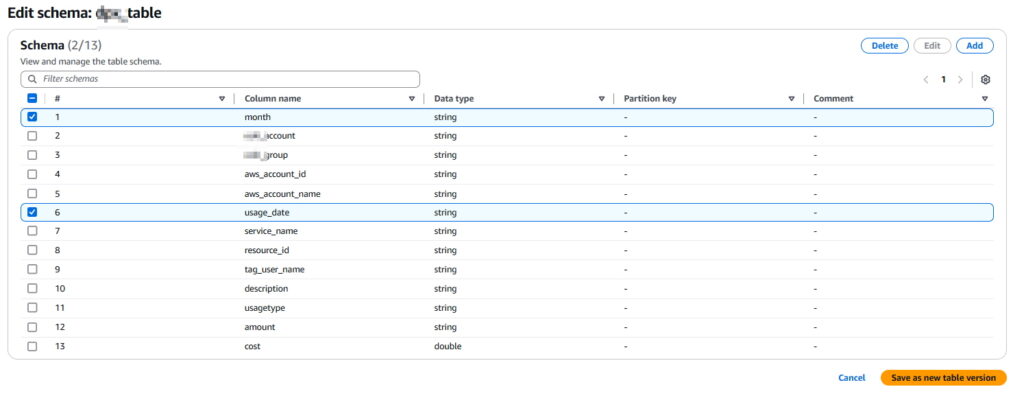
-기존에 date 였던 Data type 을 string 으로 변경
Quicksight > Dataset > edit dataset 해서 변경된 스키마가 반영되도록 refresh 해준 뒤 “PUBLISH & VISUALIZE”
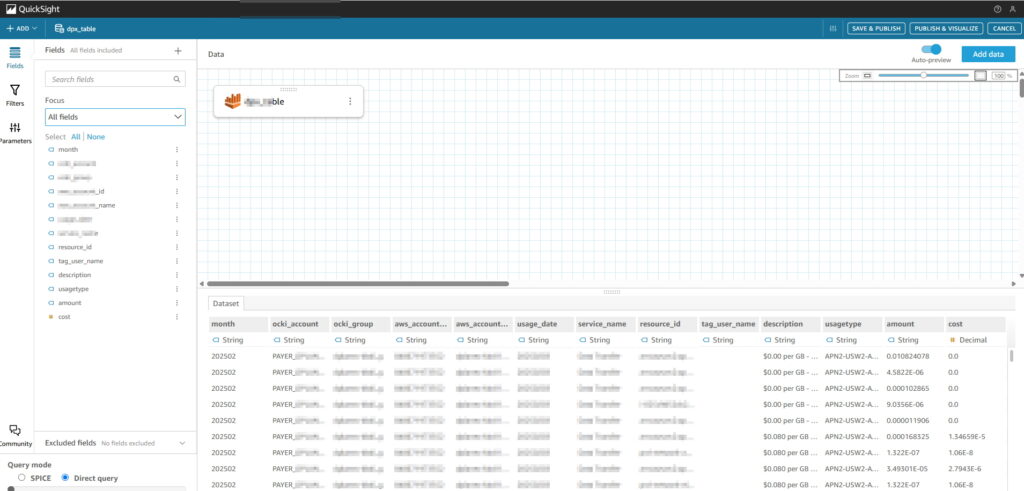
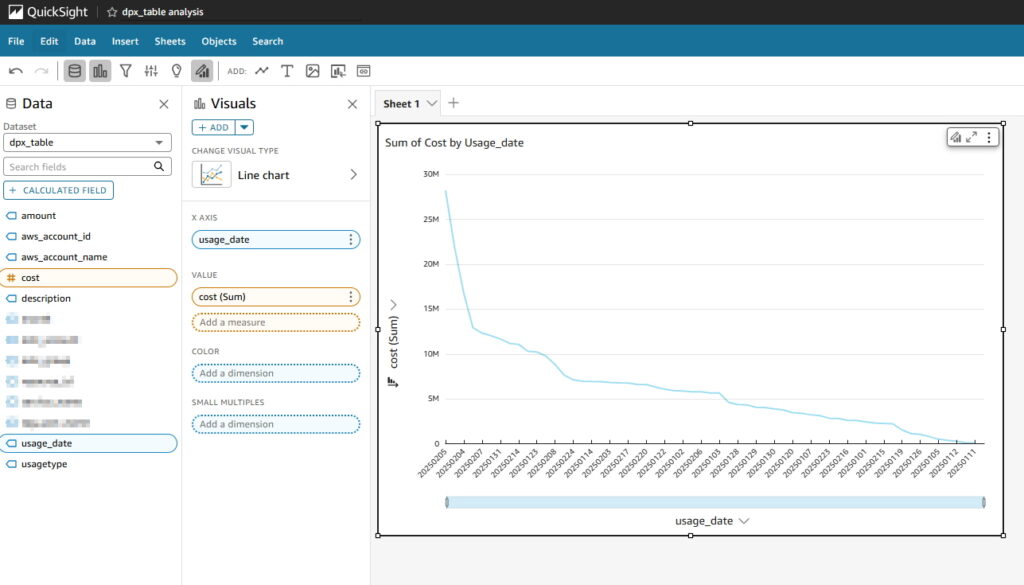
다시 Visualize 해서 그래프 생성해보면 날짜 인식 잘 되는것 확인 가능
2)데이터베이스 추가하는 경우
추가 데이터가 발생하여 함께 분석 해야하는 경우 데이터베이스를 추가하는 방법이다.
S3 데이터 추가 – 3월,4월 데이터 추가 업로드
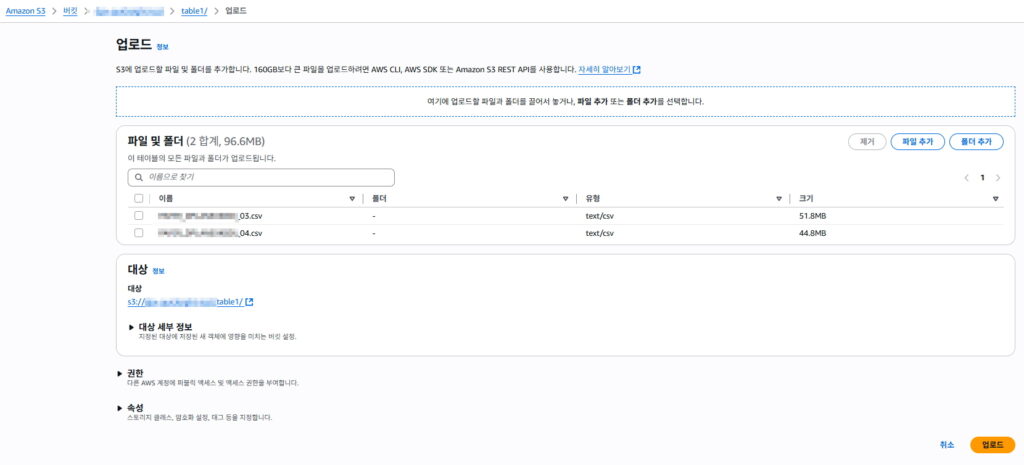
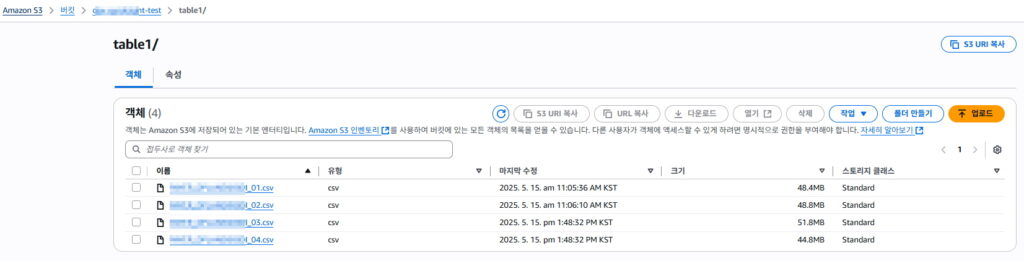
별도의 다른 리소스 업데이트 하지 않아도 자동으로 반영됨
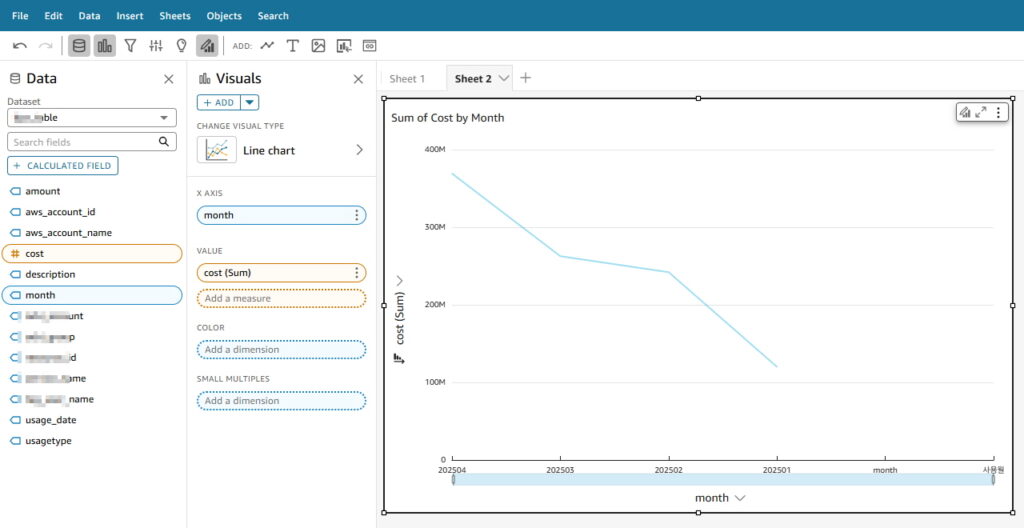
202503,202504 데이터 추가된 것 확인 가능
데이터 제거 역시 동일
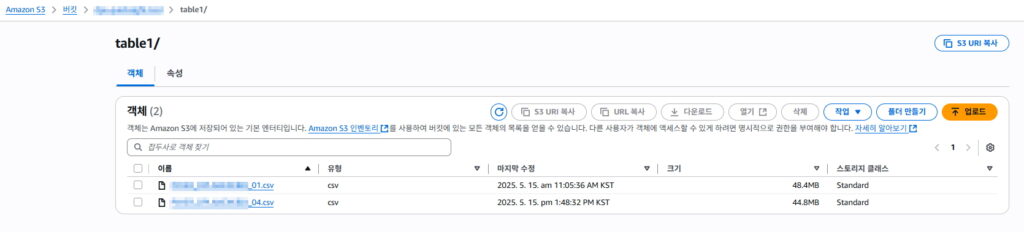
2월,3월 데이터 S3에서 삭제
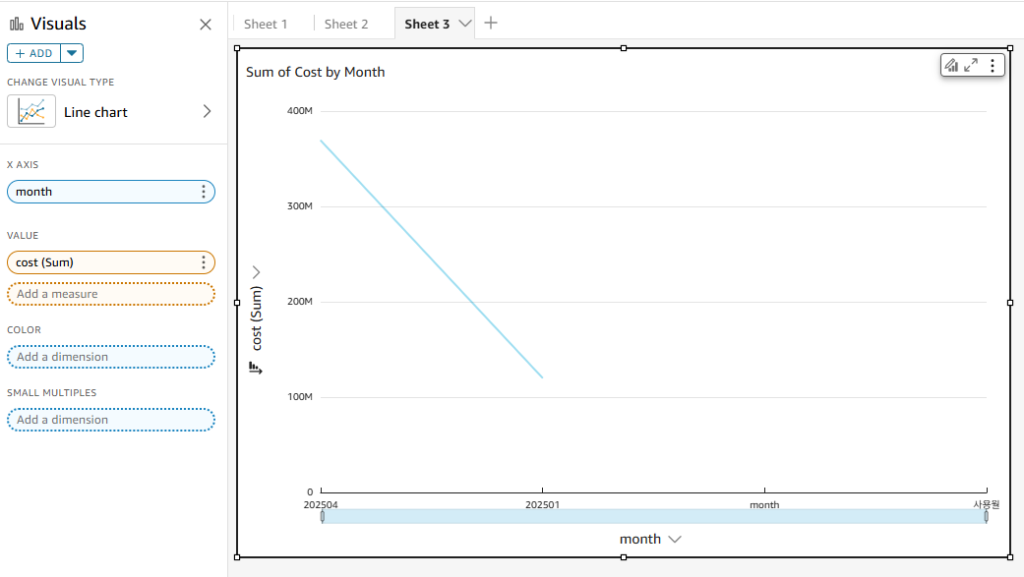
별도의 다른 리소스 업데이트 없이 quicksight 에 바로 반영되어 202502,202403 데이터 제외된 결과 보여줌
3. 결론
Amazon Athena 와 Amazon QuickSight를 이용하면 데이터 분석에 대한 지식이나 별도의 복잡한 과정없이 간단하게 데이터를 시각화 할 수 있었습니다. 하지만 좀 더 정교한 시각화와 정확히 필요한 데이터를 얻기 위해서는 Quicksight 를 통한 Visualizing 에 대한 추가적인 연구가 필요합니다.
참고문서
https://docs.aws.amazon.com/quicksight/latest/user/welcome.html
https://docs.aws.amazon.com/ko_kr/athena/latest/ug/what-is.html