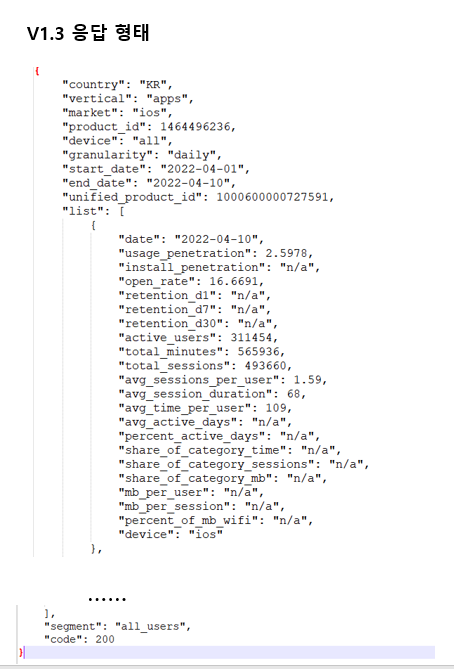
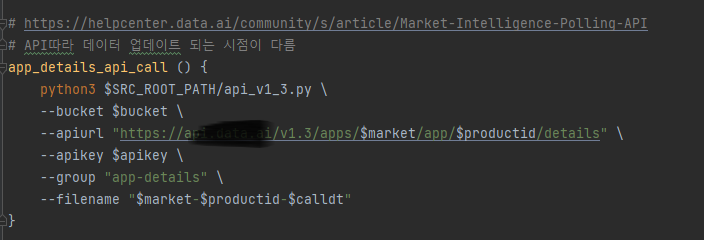
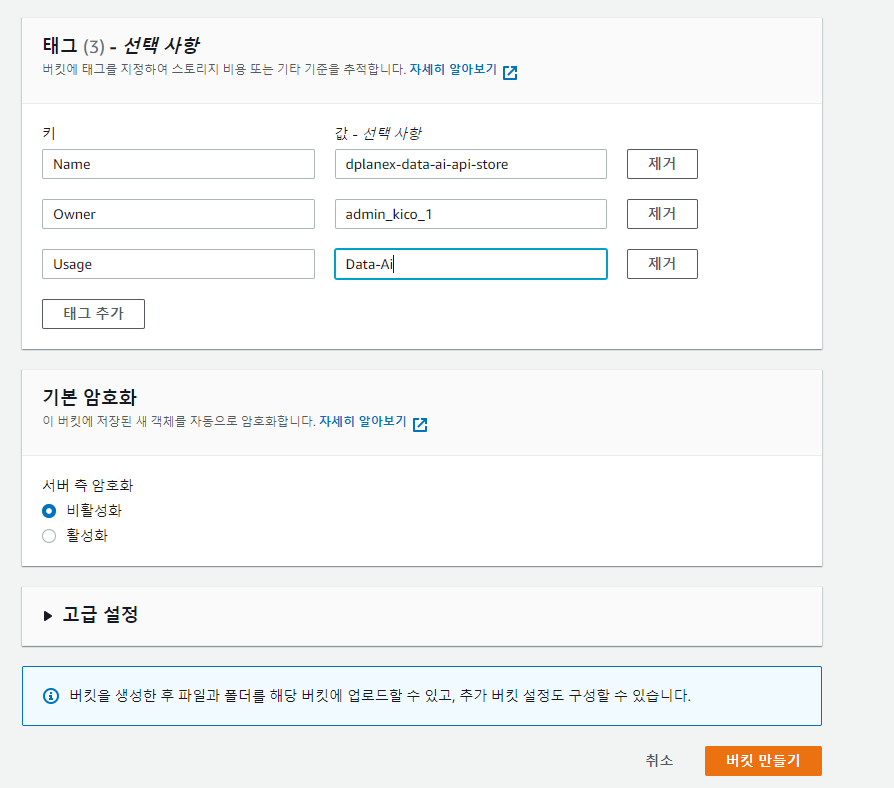
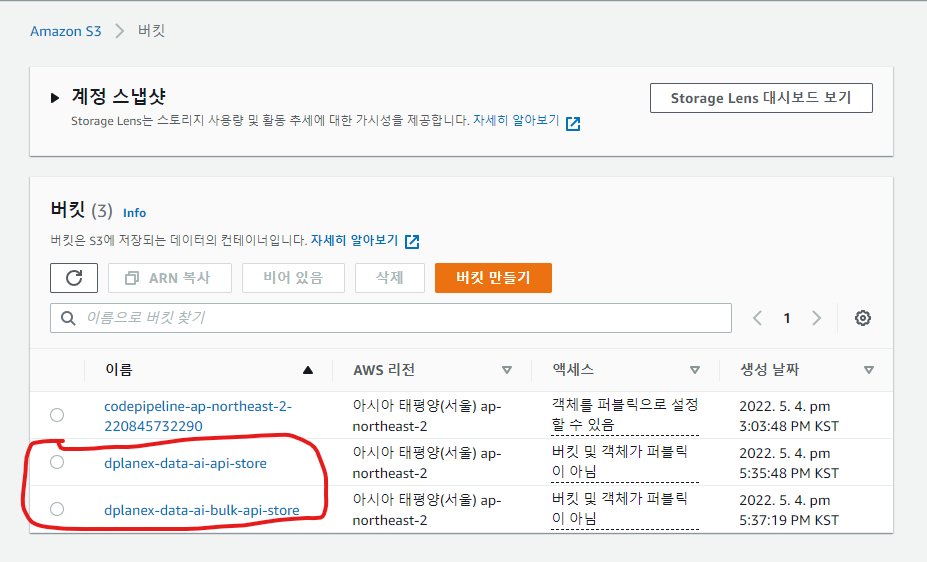
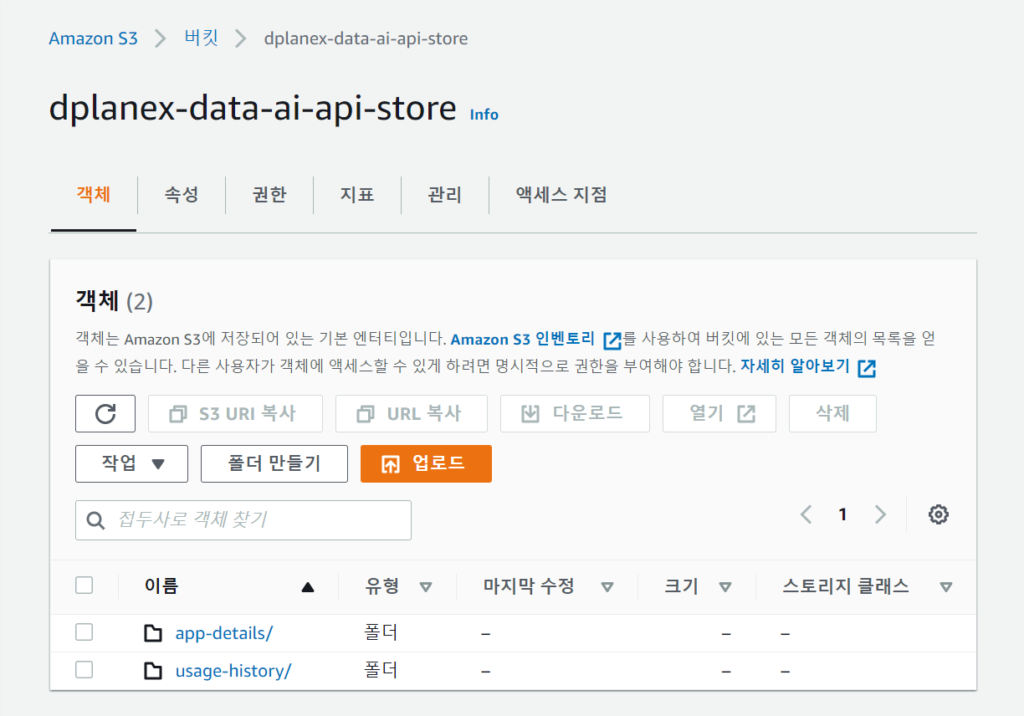
def bulk_api_call(bucket, apiurl, apikey, download_path, download_url_name):
try:
start = time.time()
s3 = boto3.client('s3')
payload = {}
headers = {
'Authorization': 'Bearer {}'.format(apikey),
'Accept': 'application/json'
}
response = requests.request("GET", apiurl, headers=headers, data=payload)
print(response.status_code, response.text)
json_data = json.loads(response.text)
for i in range(len(json_data['data']['urls'])):
download_start = time.time()
download_url = json_data['data']['urls'][i]
print("url >>>> {}".format(download_url))
if "dimensions" == download_url_name:
if "name=metrics" in download_url:
continue
if "metrics" == download_url_name:
if "name=dimensions" in download_url:
continue
upload_file_path, file_name = get_object_path(download_url)
payload = {}
headers = {
'Authorization': 'Bearer {}'.format(apikey),
'Authentication': '{}'.format(apikey)
}
response = requests.request("GET", download_url, headers=headers, data=payload)
print(response.status_code)
save_directory = "{}/{}".format(download_path, upload_file_path)
if not os.path.exists(save_directory):
os.makedirs(save_directory, True)
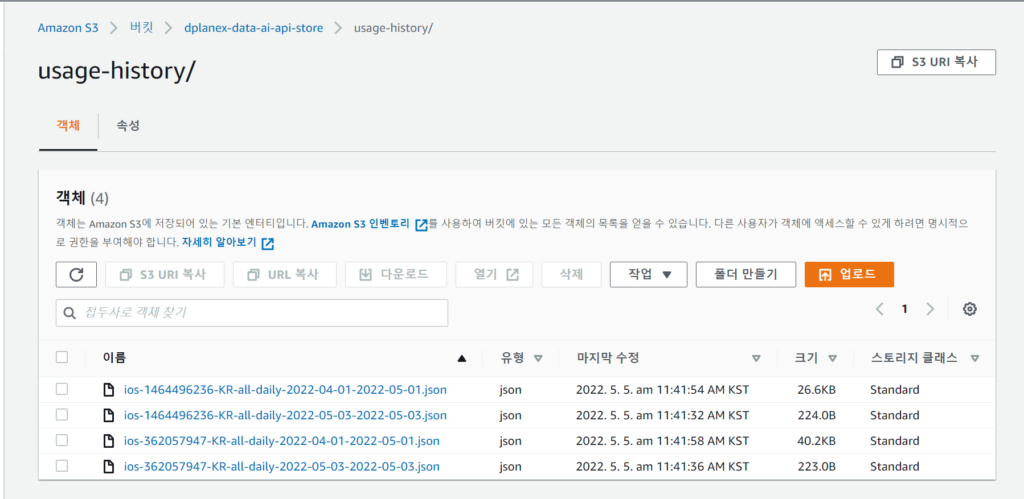
f = open("{}/{}.csv.gz".format(save_directory, file_name), 'wb')
for chunk in response.iter_content(chunk_size=512 * 1024):
if chunk: # filter out keep-alive new chunks
f.write(chunk)
f.close()
s3.upload_file("{}/{}.csv.gz".format(save_directory, file_name), bucket,
"{}/{}.csv.gz".format(upload_file_path, file_name))
os.remove("{}/{}.csv.gz".format(save_directory, file_name))
print("{}. download elapsed time : {} sec".format(i, time.time() - download_start))
print("total elapsed time : ", time.time() - start, "sec")
return {
'statusCode': 200,
'body': json.dumps('success')
}
except Exception as e:
print(e)
return {
'statusCode': 400,
'body': json.dumps('fail {}'.format(e))
}