

Why Amazon EKS Upgrade?
EKS 는 표준화 된 인터페이스와 오토 스케일링, AWS Loadbalancer 등과의 연계를 통한 안정적인 서비스 운영에 필요한 다양한 기능을 관리형 서비스로 제공하여 기존 설치 형 쿠버네티스 서버와는 차이점이 있습니다. 관리 측면에서 효율적으로 도움을 주는 반면, 기능이 자주 업그레이드 되어 Cluster 를 운영하는 입장에서는 다소 부담이 될 수도 있습니다. 따라서, 이번 페이지에서는 그 Amazon EKS 를 좀 더 간단하게 업데이트 해보는 내용으로 작성해보겠습니다.
AWS EKS 의 경우, Kubernetes 버전이 정식 Release 이후 약 1년 동안 Support 해줍니다.
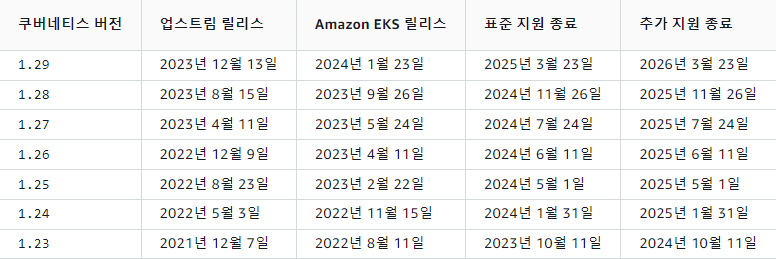
위와 같이 Extended support 라 하여 기존 Support 에 Extended Support 기간 1년을 지원해줍니다. 하지만, 안정적으로 Standard Support 받기 위해서는 기한 내에 Cluster의 Kubernetes 버전을 최신으로 업데이트 해야 합니다.

그리고 Amazon Official(Link) 에 따르면, Standard와 Extended 기간의 Cluster 비용이 2024년 04월 01일 부터 달라진다고 하니, 업그레이드 된 기능 Support 뿐만 아니라, 추가 비용을 내지 않기 위해서는 Standard Support 기간에 Cluster 업데이트 해줘야 될 것으로 보입니다.
Upgrade Process – Cluster
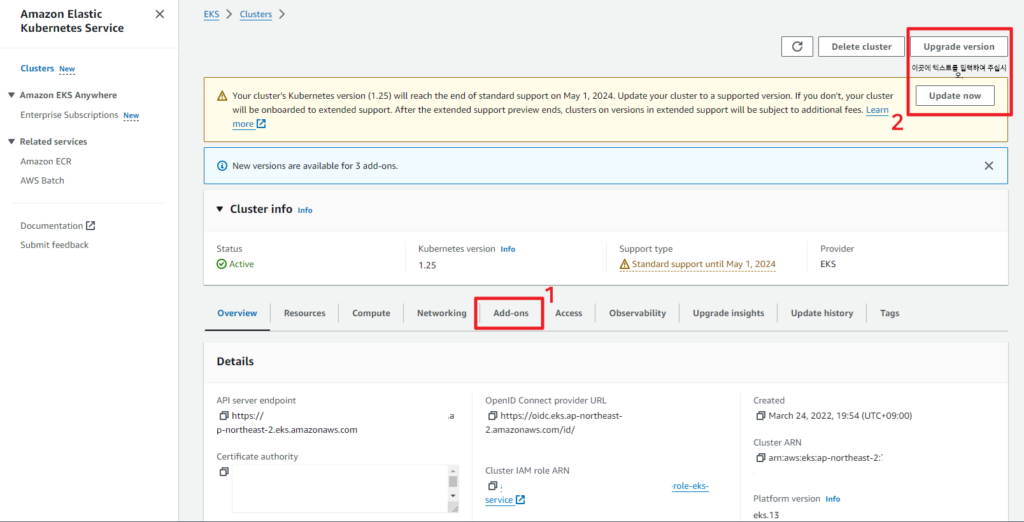
AWS Console 상에서도 현재 업데이트가 가능한 Cluster는 위와 같이 Update now 버튼이 활성화 되어있습니다. 이번 시간에는 Kubernetes 1.25 버전에서 1.26 버전으로 업데이트 해보겠습니다. Cluster를 업데이트 하기에 앞서 현재 Cluster 내에서 사용되고 있는 낮은 버전의 Add-ons를 먼저 업데이트 하겠습니다.
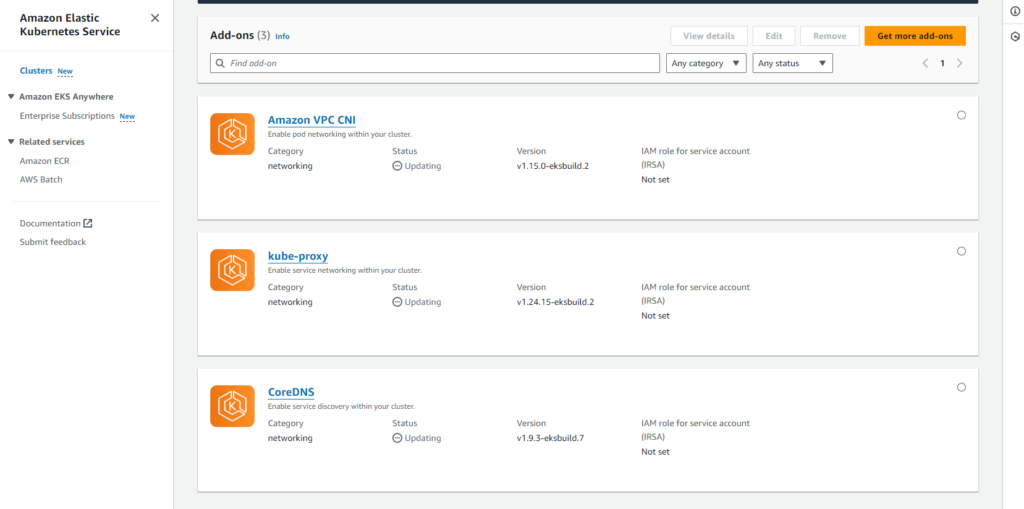
Add-ons 를 눌러 현재 사용하고 있는 Add-ons 를 Cluster Version에 맞추어 업데이트 해줍니다.
- Amazon VPC CNI : Amazon EKS 클러스터에 있는 Pod 네트워킹 용 네트워킹 플러그인 입니다. CNI 는 Kubernetes 노드에 VPC IP 주소를 할당하고 각 노드의 Pods에 대한 필수 네트워킹을 구성하는 역할을 합니다. 관련된 정보 및 호환 버전은 다음 URL 을 참고하시기 바랍니다.
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/managing-vpc-cni.html
- kube-proxy : 서비스 정의를 네트워킹 규칙으로 변환하는 쿠버네티스 에이전트입니다. 클러스터의 모든 노드에서 실행되고 API 서버와 통신하여 업데이트를 수신합니다. 그런 다음 이런 업데이트는 노드 내부의 kube-proxy에 의해 이루어집니다. 관련된 정보 및 호환 버전은 다음 URL 을 참고하시기 바랍니다.
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/managing-kube-proxy.html
- CoreDNS : Kubernetes 클러스터 DNS로 사용할 수 있는 유연하고 확장 가능한 DNS 서버입니다. 하나 이상의 노드가 있는 Amazon EKS 클러스터를 시작하면 클러스터에 배포된 노드 수에 관계없이 CoreDNS 이미지의 복제본 2개가 기본적으로 배포됩니다. 관련된 정보 및 호환 버전은 다음 URL 을 참고하시기 바랍니다.
https://docs.aws.amazon.com/ko_kr/eks/latest/userguide/managing-coredns.html
다음은 우측 상단의 Upgrade version 또는 Update now 버튼을 누르면 다음과 같은 창이 뜹니다.

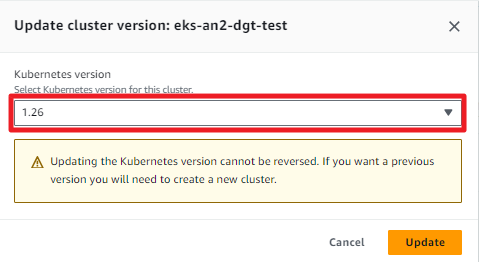
Amazon EKS Kubernetes version 은 현재 1.29 까지 출시되어있으나, Cluster 는 한번에 여러 단계를 업데이트 하지 못하며, 한 단계 씩 업데이트 해야 합니다. 업데이트 버튼을 누르면 업데이트가 진행되고 이 프로세스는 약 25분 정도 소요됩니다 . Control Plane 업그레이드 프로세스 중에 클러스터를 계속 사용할 수 있어, 기존 서비스는 계속 사용 가능하지만, 사소한 서비스 중단이 발생할 수 있습니다.

업데이트가 완료되면, 위와 같이 Kubernetes version 이 1.26으로 변경된 것을 확인하실 수 있습니다.
Upgrade Process – Custom AmI & Templates (eks-node-1.26)
다음은 노드 그룹의 버전을 업데이트 할 차례입니다. 업데이트 방법은 현재 있는 1.25 노드 그룹 별개로 1.26 노드 그룹을 한 개 더 띄워서 기존에 있는 pod 들을 Drain 하여 기존 노드에서 안전하게 Pod들을 축출하여 업데이트 된 노드 그룹으로 서비스를 옮기는 방식으로 진행해보겠습니다. 안전한 축출은 Pod의 Container를 gracefully terminate 하도록 합니다.
1.26의 노드 그룹을 생성하기 전에 AWS Community AMI 에서 공식적으로 제공되는 1.26 AMI 로 만든 시작 템플릿을 만들겠습니다.
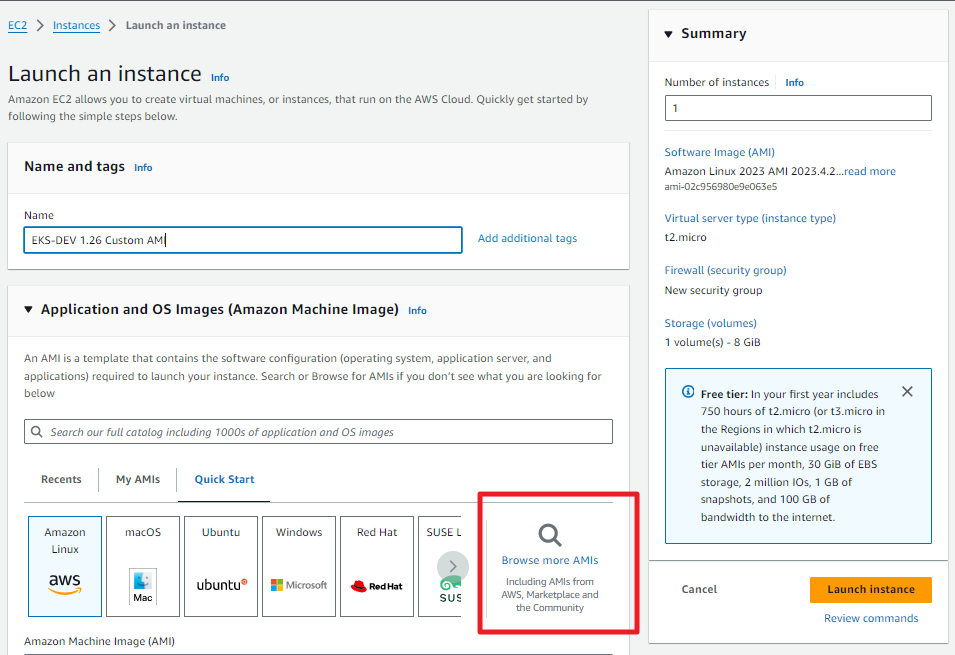
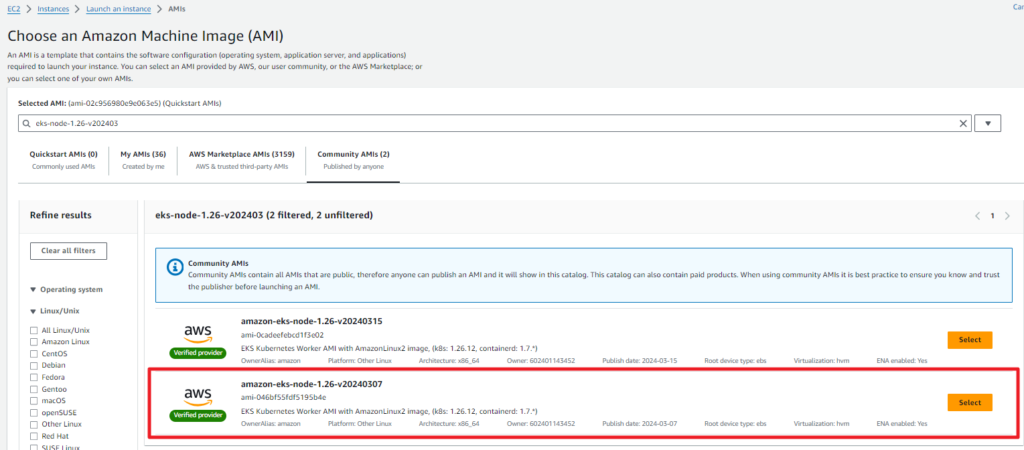


Launch Instance 에서 AMI 쪽에서 돋보기를 클릭하여 Community AMIs 에서 필요한 버전 (eks-node-1.26) 을 검색해서 Select 해준 후 사용자 정의 값에 따라 EKS Node 용 인스턴스를 만들어 줍니다. 이렇게 Custom AMI 를 만들어주는 이유는 EKS에 최적화된 OS 버전 내에 EKS 노드 에 필요한 Component 들 (이번의 경우엔 Kubernetes 1.26 버전)이 이미 구성 되어 있어서, 사용 측면에서 좀 더 편리하고 효율적으로 관리할 수 있습니다.
그 다음은 만들어진 인스턴스를 선택하여 AMI 및 시작 템플릿을 만들어 줍니다.
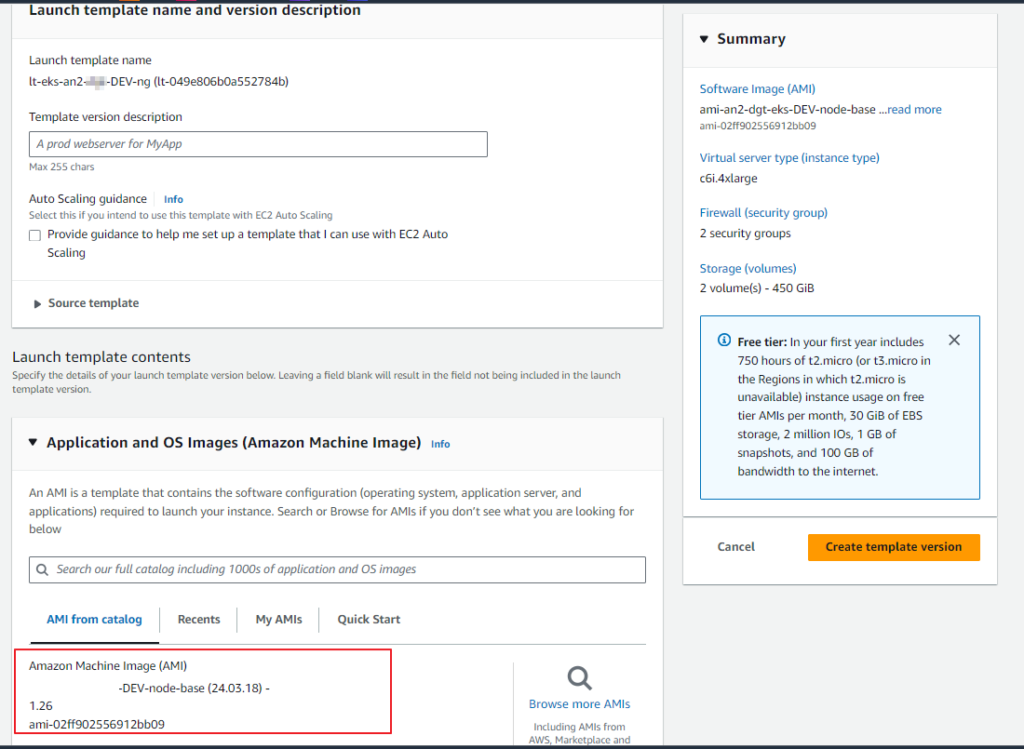
Upgrade Process – Add Node Group
이제 Cluster는 업데이트 되었지만, 노드 그룹은 여전히 1.25 인 EKS 환경에 1.26 버전의 노드 그룹을 추가해보도록 하겠습니다.
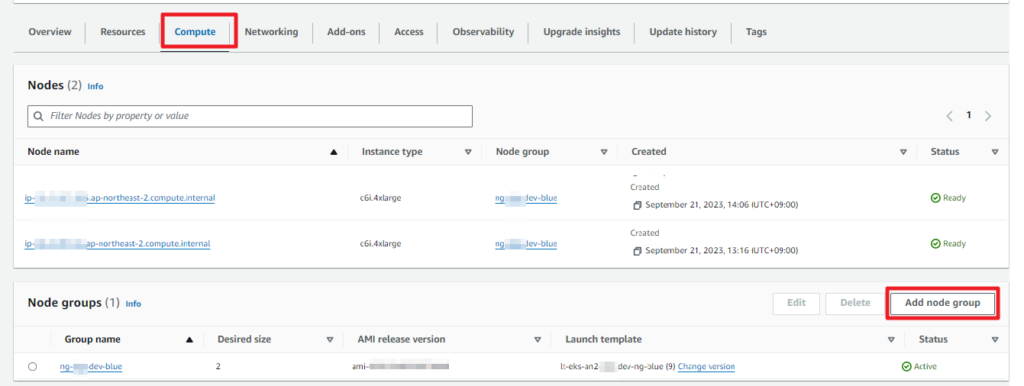
EKS Console 에서 Compute 메뉴에서 Add node group 을 통해 신규 노드 그룹을 추가 합니다.

사용하시고자 하는 노드 그룹 명과 IAM role 을 입력하고, Launch template 은 이전에 1.26 AMI를 통해 만들어준 시작 템플릿을 선택해 줍니다.
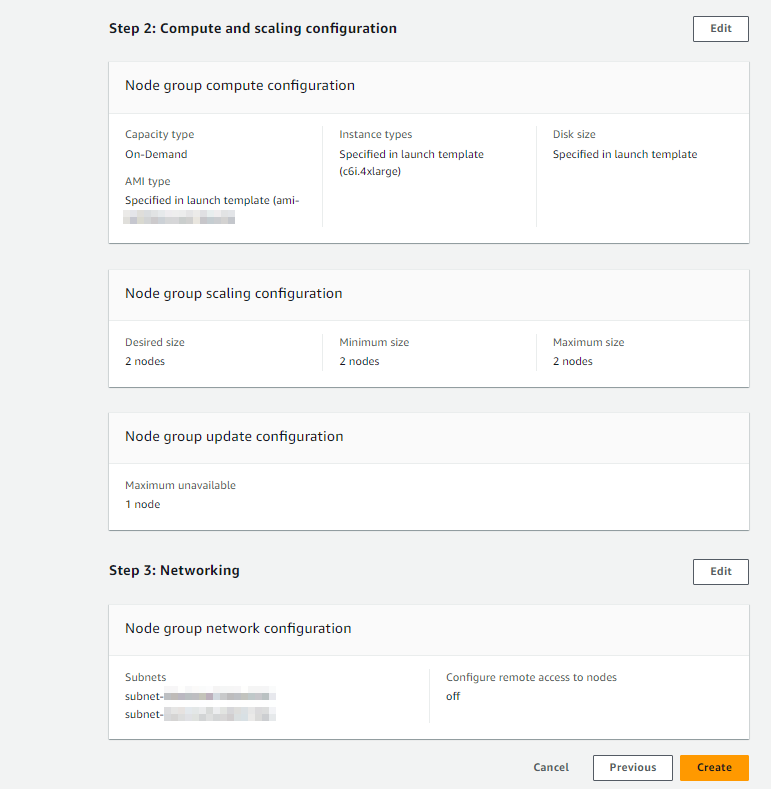
시작 템플릿으로 노드 그룹을 만들게 되면 compute configuration 부분은 Capacity type을 제외한 나머지는 자동 입력됩니다. Network의 subnet까지 지정을 해주고 생성 전 preview 확인 후 생성해 줍니다.

신규 노드 그룹이 생성되는 데에는 약 15~20분의 시간이 소요됩니다.
Upgrade Process – Drain Node
노드 그룹이 생성이 완료되어서 EKS에 bastion 서버를 통해 접속해서 노드를 조회해보면 기존 1.25 버전의 노드와 1.26 버전의 노드가 함께 조회가 됩니다.
- kubectl get no -o wide

현재 모든 Pod 들은 1.25 버전의 노드 들에 떠있는 상태이므로, 기존 노드들을 Drain 해줌으로써 Pod 들을 안전하게 축출하는 작업을 진행하겠습니다.
- kubectl drain <노드명>

이번 환경의 경우에는 위 명령어를 수행했을 때 위와 같은 에러가 발생했습니다. 위 명령어는 대상 노드의 파드가 아래의 경우에 속하는 경우 동작하지 않습니다.
- Pod가 emptyDir 을 사용하여 local data 를 저장하는 경우
> emptyDir를 사용하여 local data를 저장하는 Pod가 해당 노드 에 있는 경우, 이 Pod 를 삭제 시 해당 데이터 또한 삭제되므로 수행되지 않습니다. 해당 파드가 제거되어도 문제가 없는 경우에는 –delete-local-data 플래그를 drain 명령어에 추가하여 수행합니다.
- 해당에 데몬셋(daemonset)이 구동되고 있는 경우
>데몬셋에 속한 Pod 가 해당 노드 에 구동 되고 있는 경우, kubectl drain 명령이 수행되지 않습니다. 데몬셋 컨트롤러는 노드가 unschedulable 상태에 있더라도 이를 무시하고 해당 노드에 Pod 를 스케줄하여 배치할 수 있습니다. 데몬셋에 속한 Pod 가 있는 경우에는, –ignore-daemonsets 플래그를 추가하여 해당 Pod 를 축출 대상에서 제외할 수 있습니다.
- Kubernetes의 컨트롤러에서 관리되지 않는 Pod 가 구동 되고 있는 경우
>Kubernetes에서는 Deployment, Statefulset, DaemonSet, ReplicaSet, Job과 같은 컨트롤러가 관리하지 않는 Pod 가 해당 노드 상에 있는 경우, kubectl drain 명령어는 이를 보호하기 위해서 동작하지 않습니다. –force 플래그를 추가하여 kubectl drain 명령어를 실행하는 경우, 이러한 Pod 는 클러스터에서 제거되며 Rescheduling 되지 않습니다.
따라서, kubectl drain <Node 명> –ignore-daemonsets –delete-emptydir-data –force 명령어를 통해 노드 drain 을 진행했습니다.
- kubectl drain –ignore-daemonsets –delete-emptydir-data –force

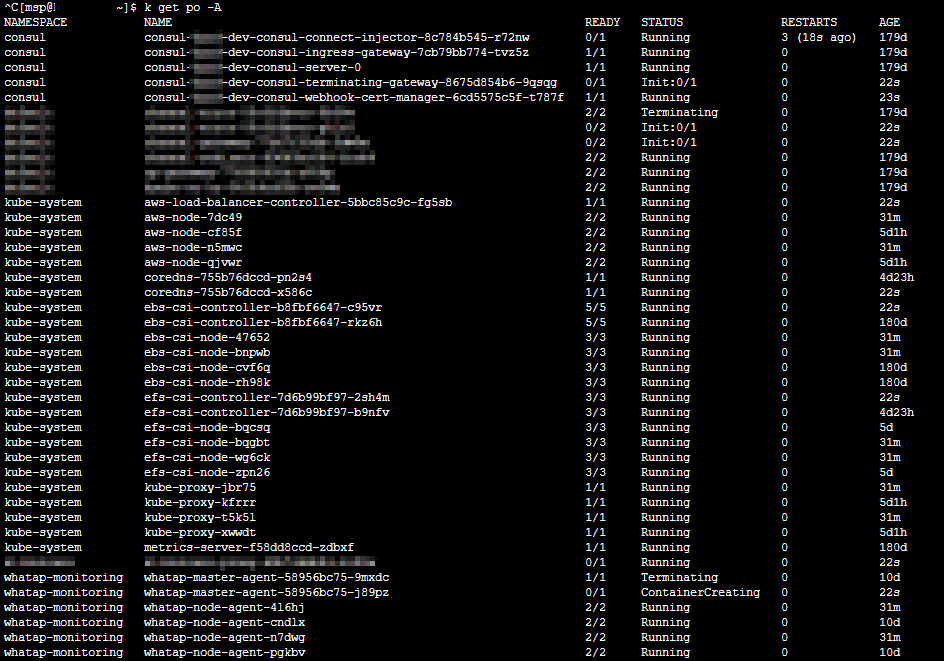
drain 과정에는 all pod 를 조회하여 pod 들이 정상적으로 축출되고 있는지 확인하였습니다. 1번 노드 가 drain 명령이 성공적으로 수행되었다면, 2번 노드 도 똑같이 수행해 줍니다.

kubectl drain 명령이 성공적으로 수행되었다면, 이는 모든 pod가 안전하게 특정 노드 로부터 축출되었다는 것을 의미합니다. 그런 다음 노드 인스턴스를 정지, 재 시작 혹은 반납하여 노드를 중단하는 것이 안전합니다.

drain 이 완료된 후 노드를 재조회 해보면 기존 노드들은 Reday, SchedulingDisabled 상태인 것을 확인할 수 있습니다. 동시에, Pod 들도 신규 노드에 정상적으로 올라오고, 운영 중인 서비스도 정상인지 확인합니다. 서비스 상태가 확인이 되면 다음은 기존 노드 그룹을 삭제할 차례입니다.
Upgrade Process – Delete old node group

EKS Console 상에서 Compute 메뉴에서 기존 노드 그룹을 삭제해줍니다.
제 경우에는 노드 그룹 삭제 중 다음과 같은 에러가 발생했습니다.

이 경우에는 해당 노드 그룹에 Auto Scaling Group 에 등록이 Scale in protection 이 되어있어 발생한 것으로 걸려있는 구 노드 그룹은 삭제할 것이므로 함께 등록되어 있는 ASG 를 삭제해 줍니다.
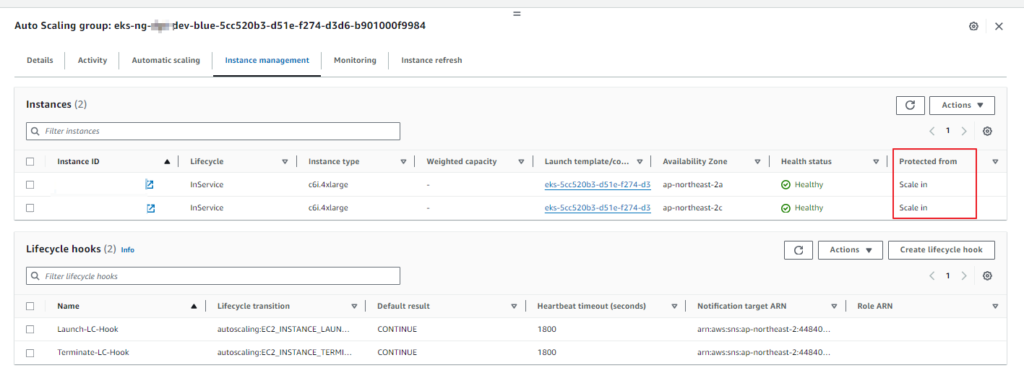

ASG를 삭제하게 되면 정상적으로 노드 그룹을 통해 생성된 인스턴스 들이 terminate 되고, 1.26 버전의 노드 그룹만 남아있게 됩니다.

이렇게 되면 Amazon EKS Kubernetes 버전 (1.25 ~> 1.26) 업그레이드 프로세스가 완료되었습니다.
Amazon EKS 업그레이드 관련해서 추가 문의가 있으시면 댓글 부탁 드립니다.
감사합니다.
Great insight! Managing cloud servers often seems complex, but Cloudways takes the stress out of the equation. Their platform delivers powerful performance without the usual technical headaches. It’s an ideal solution for those who want scalable hosting without getting lost in server configurations. Definitely worth checking out for a smoother hosting journey. Keep up the excellent work! Explore more through the link.