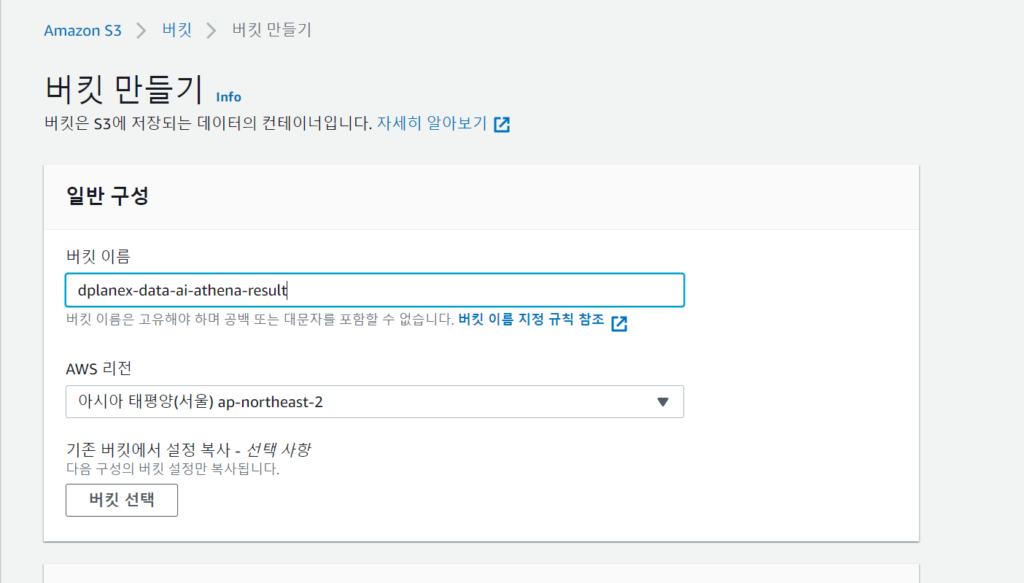
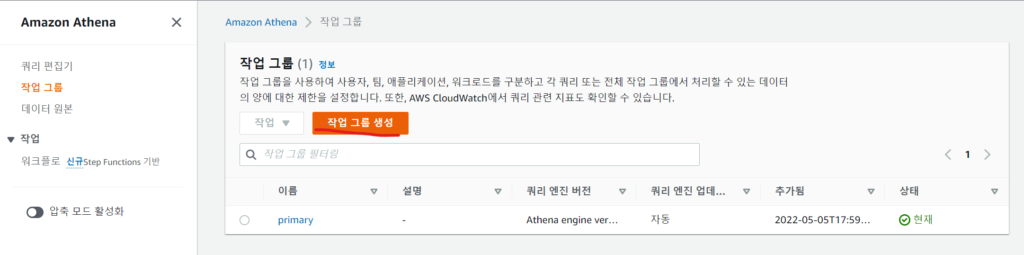
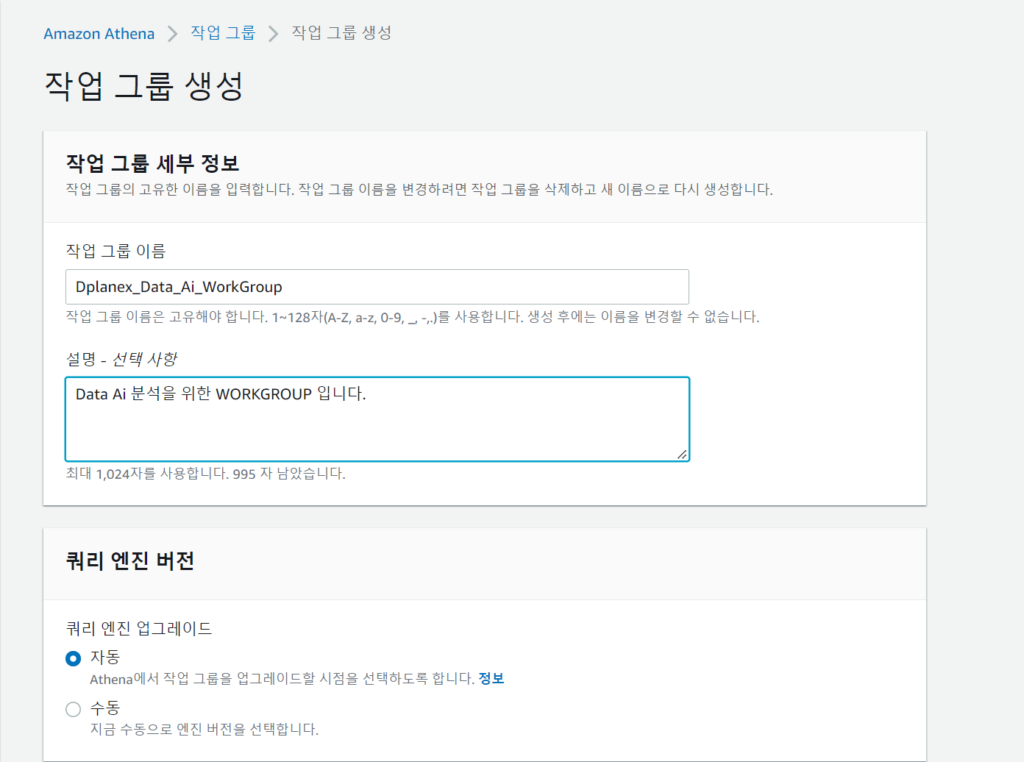
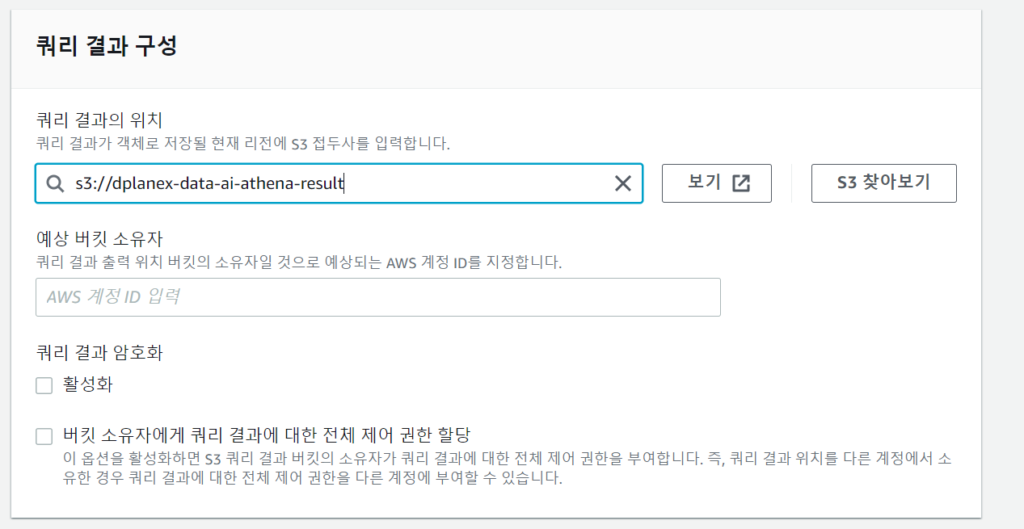
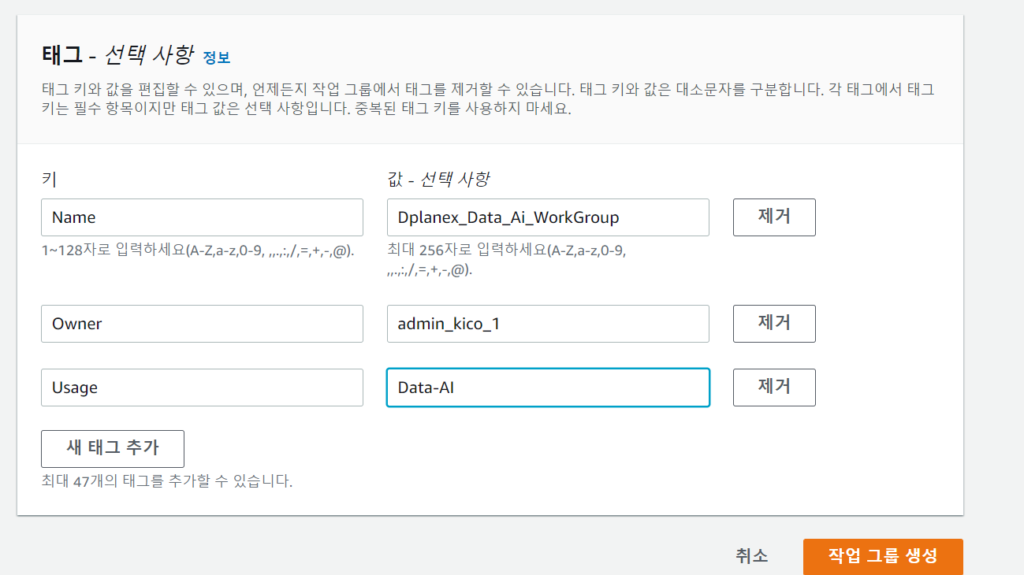
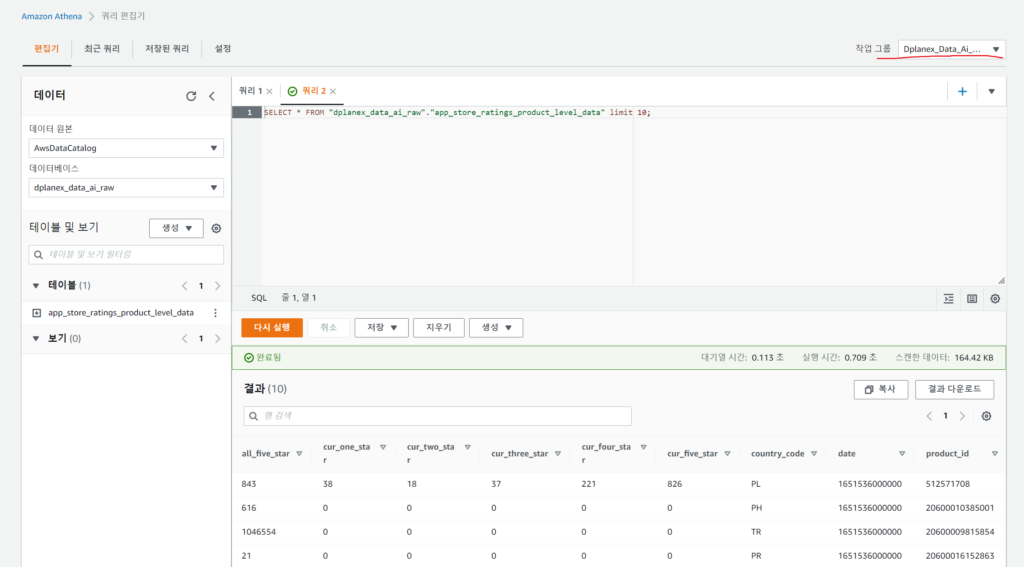
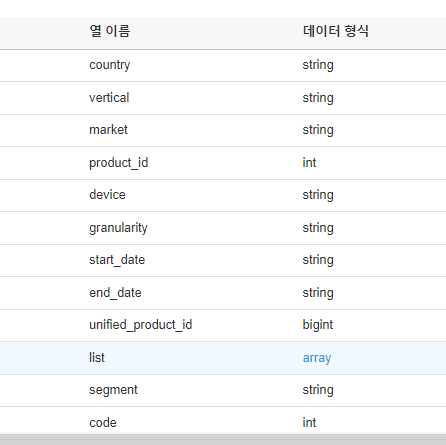
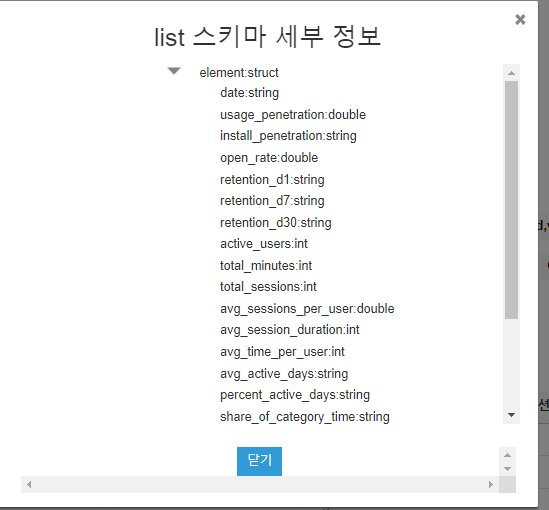
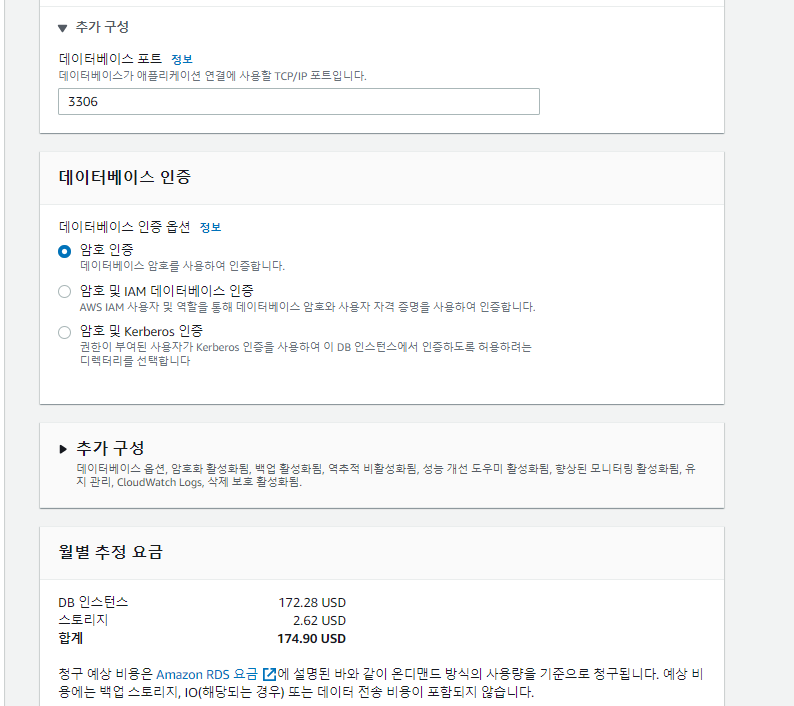
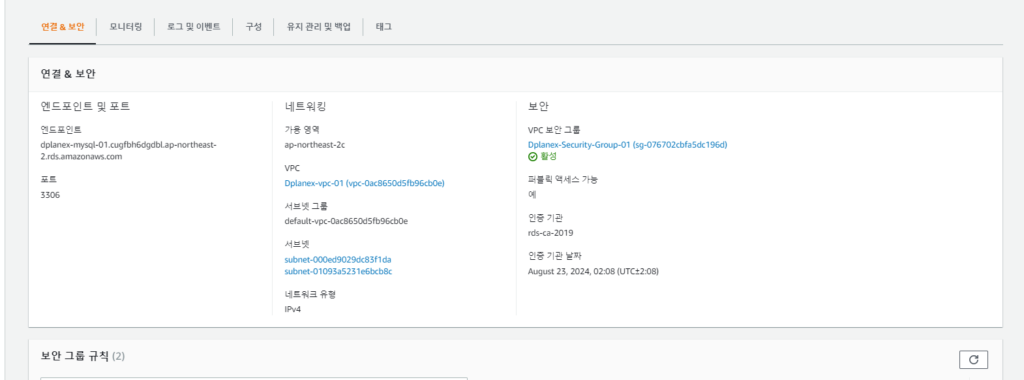
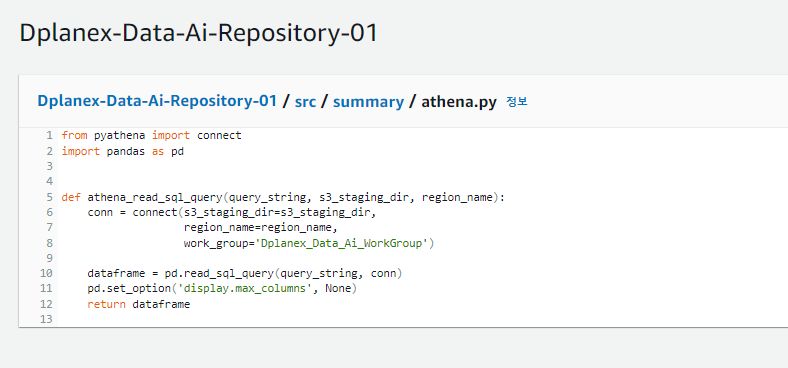
1. pyathena를 쓰면 pandas와 함께 써서 read_sql등 함수로 편하게 쿼리 결과를 읽어올 수 있습니다.
그외에 boto3, wrangler 방식이 있습니다. boto3는 기본기능만 사용할때 쓰기 쉽고, 프로그래밍 방식으로 다양하게 데이터를 읽고 쓰기를 위한다면 wrangler 방식을 도입하는 것을 권장합니다. poc과정을 준비하면서 Pyathena로 간단하게 읽는 방식을 구현하였습니다.
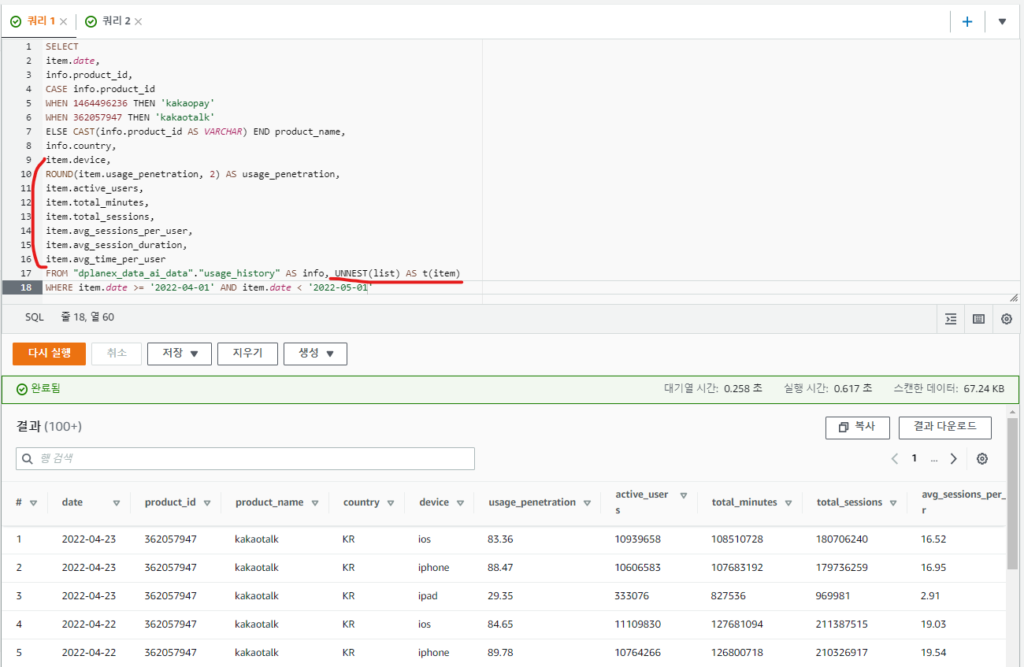
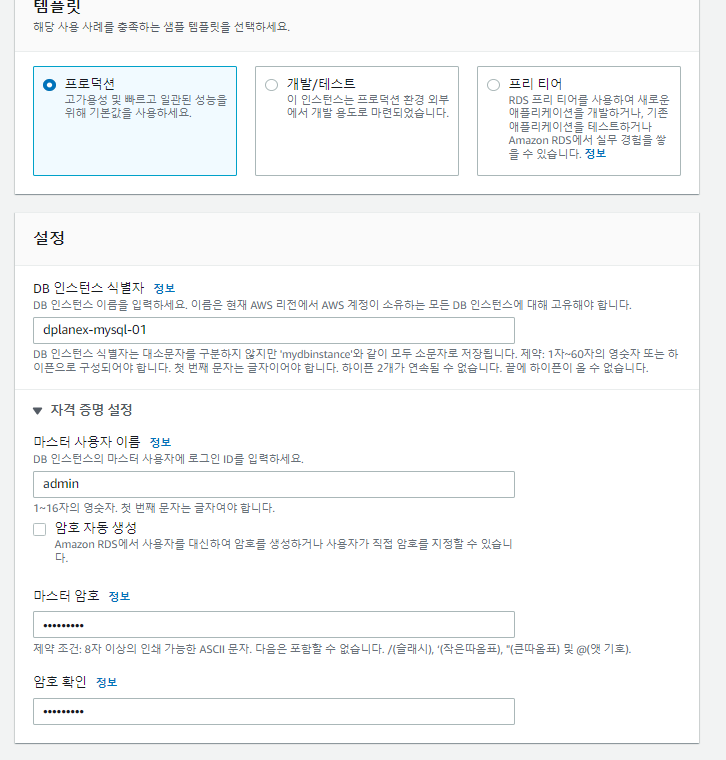
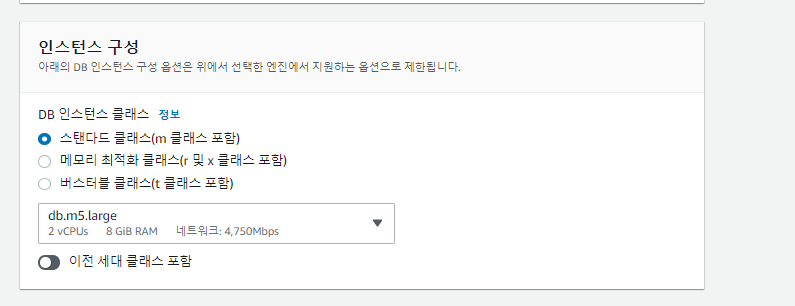
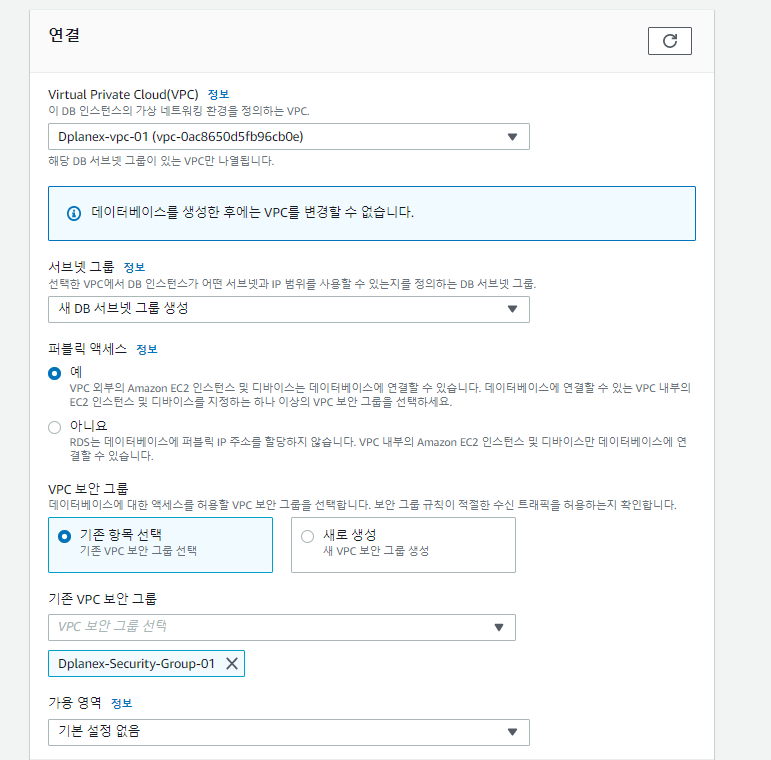
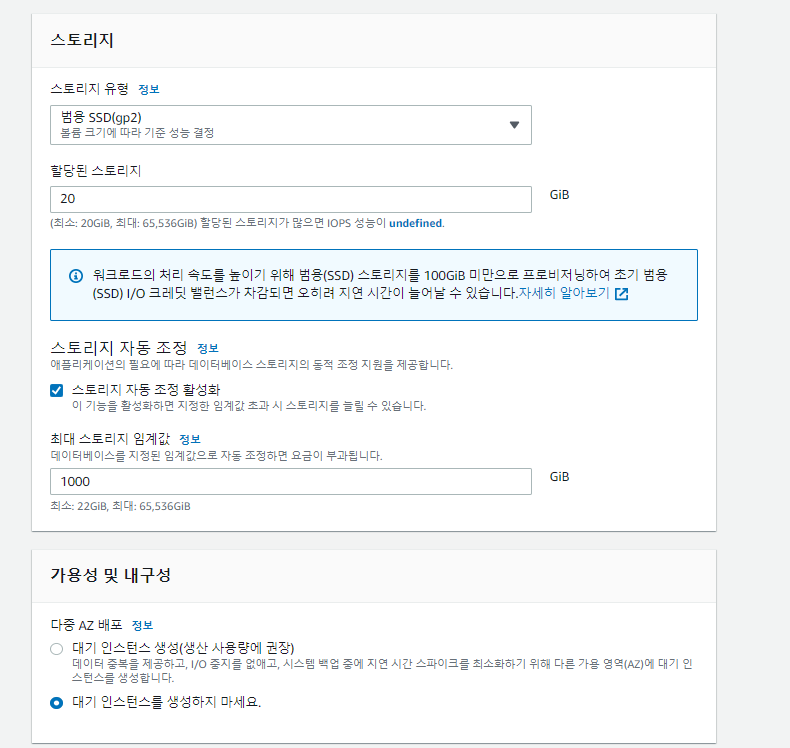
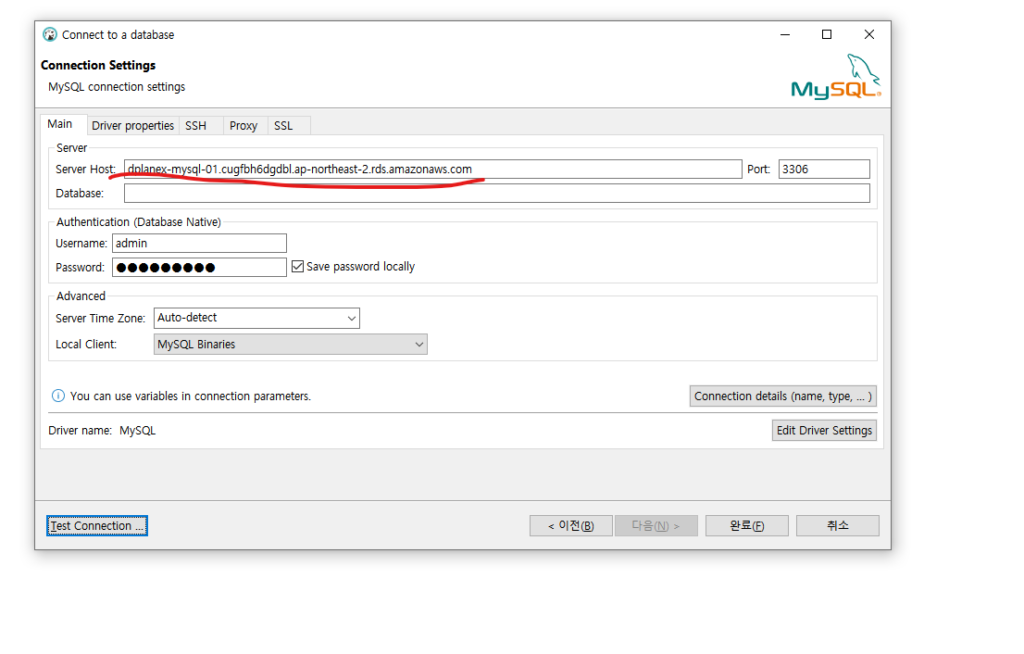
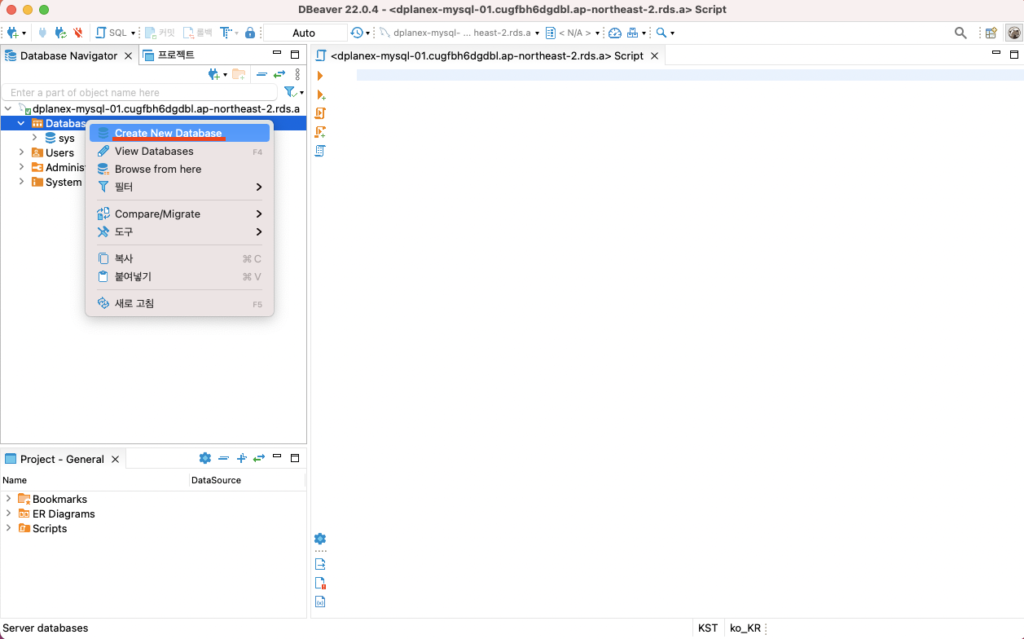
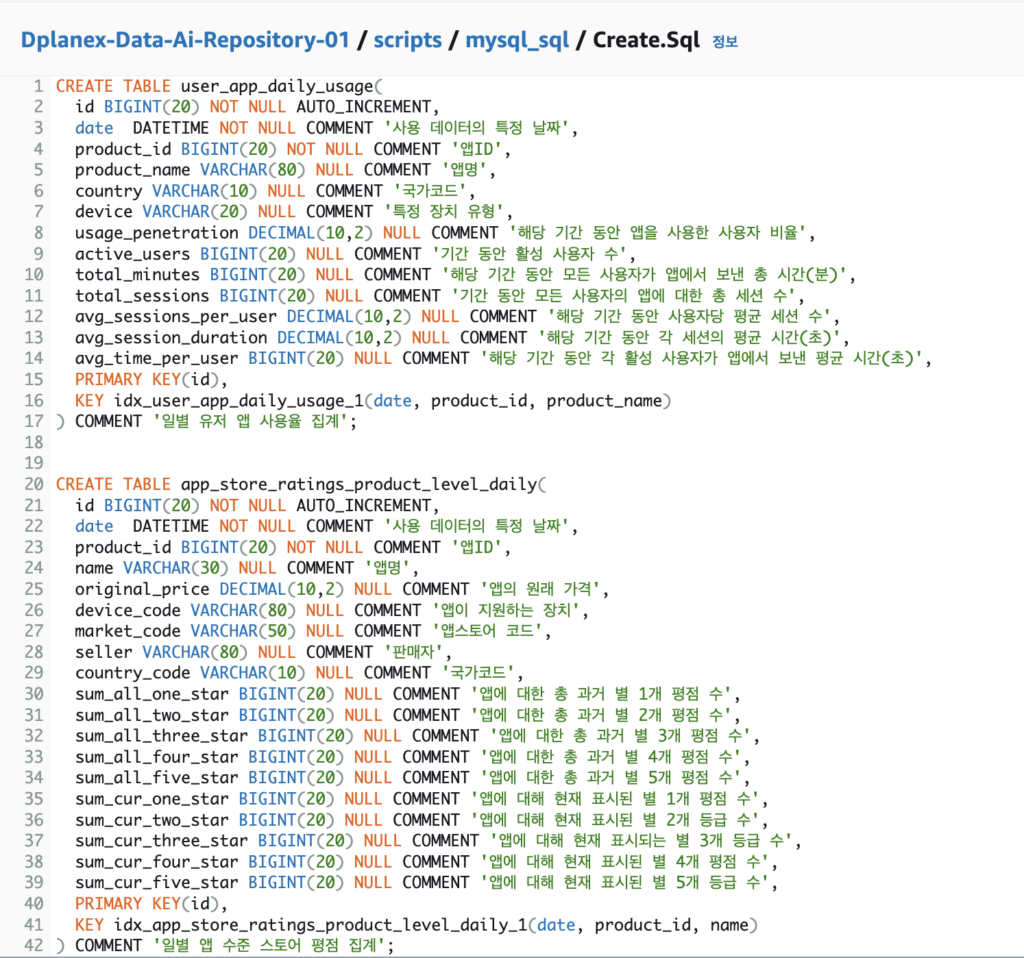
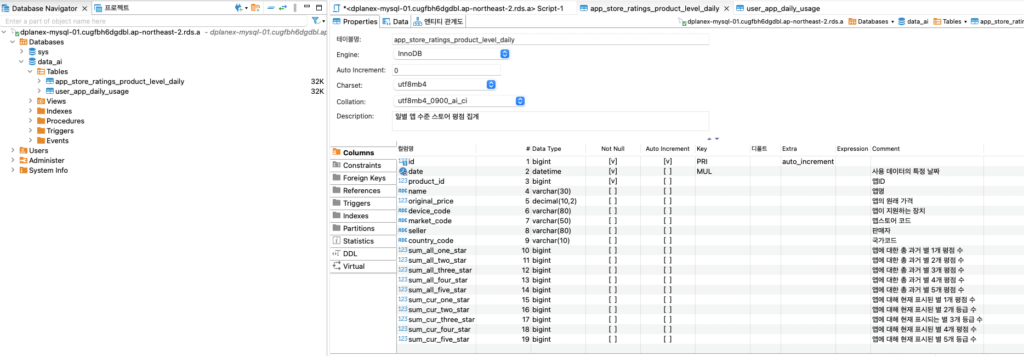
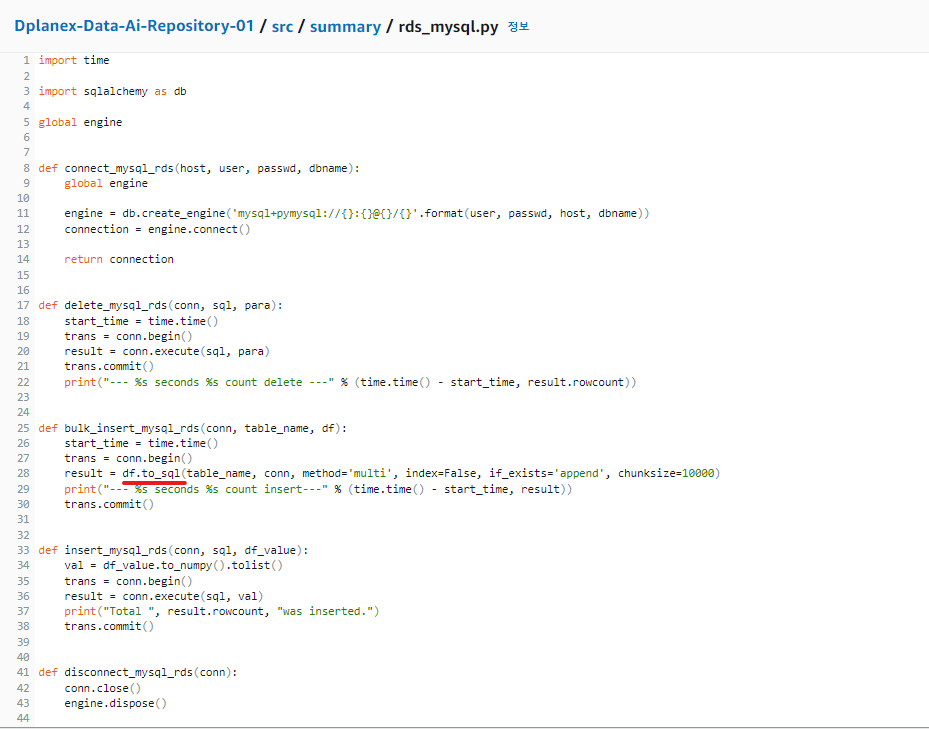
<sqlalchemy로 Mysql에 데이터 insert하기>
1. sqlalchemy 라이브러리를 통하여 python 코드와 mysql을 연결하여 사용하였습니다. Bulk insert시 pandas의 to_sql로 데이터프레임을 통째로 올리는 방법이 있고 속도가 매우 빠릅니다.
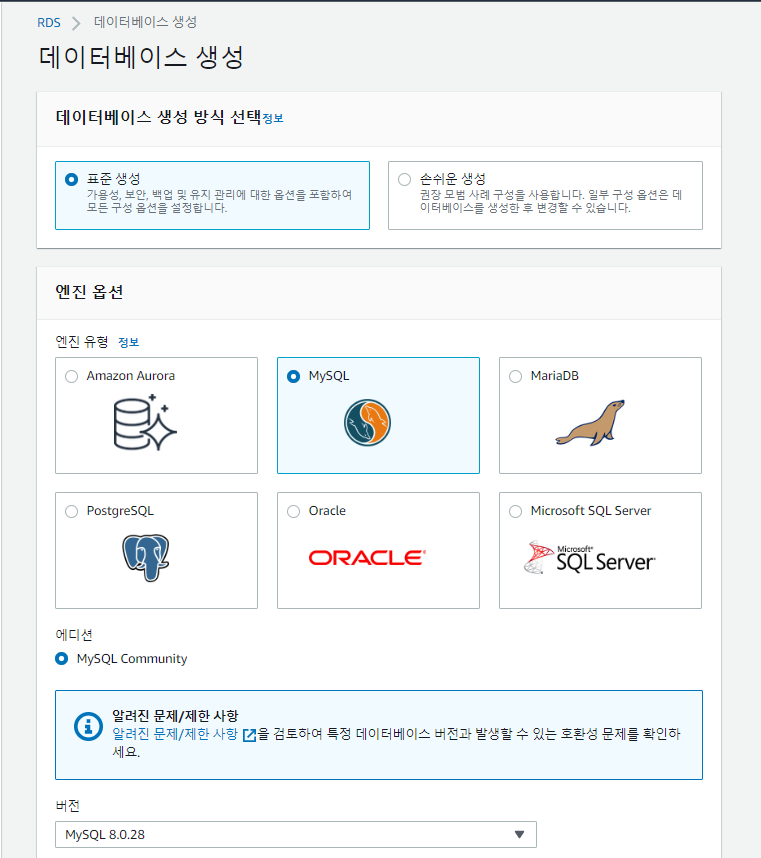
* 위에 구현한 라이브러리들을 통해 Athena 분석 쿼리 결과 RDS 에 적재되도록 구성해 놓은 배치 스크립트를 EC2에 올려 crontab에서 스케줄링합니다.
2. EC2에 배치 스크립트 크론탭으로 스케줄링 설정한 정보입니다.
* Bulk API를 0시 5분에, Glue ETL을 통한 파일변환을 01시에 적재 데이터를 그 데이터를기준으로 집계하는 배치는 2시 5분에 스케줄링하였습니다.