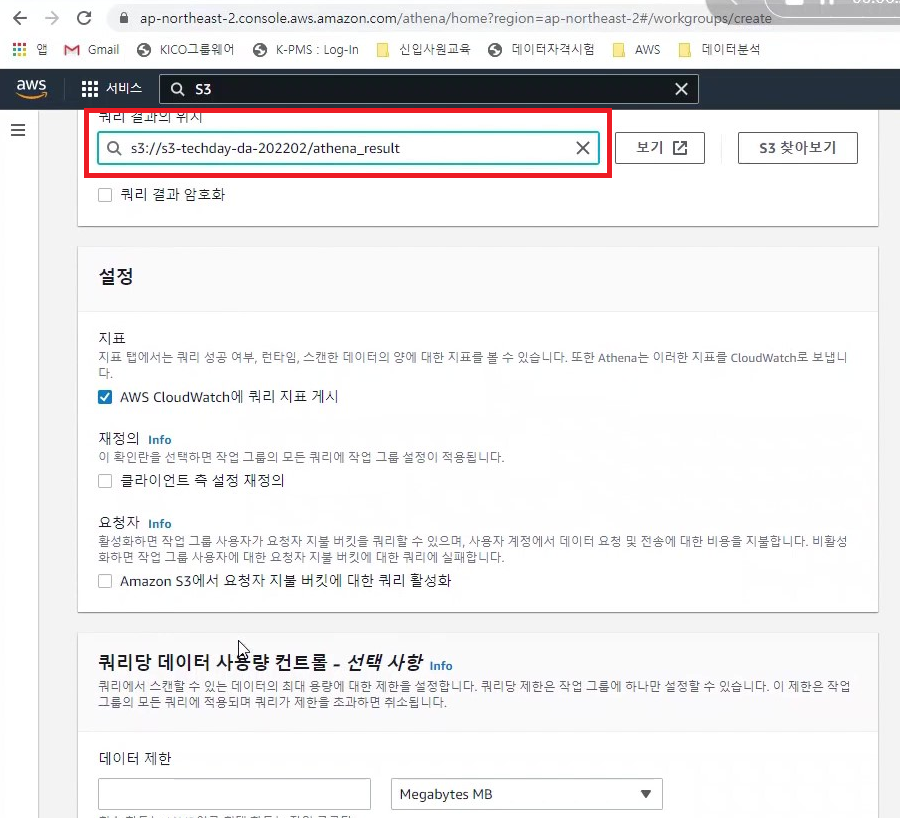
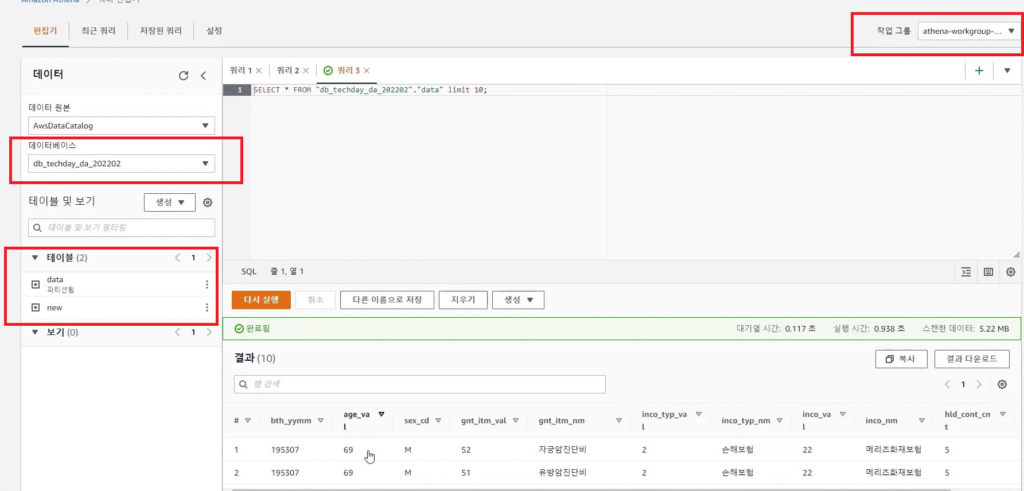
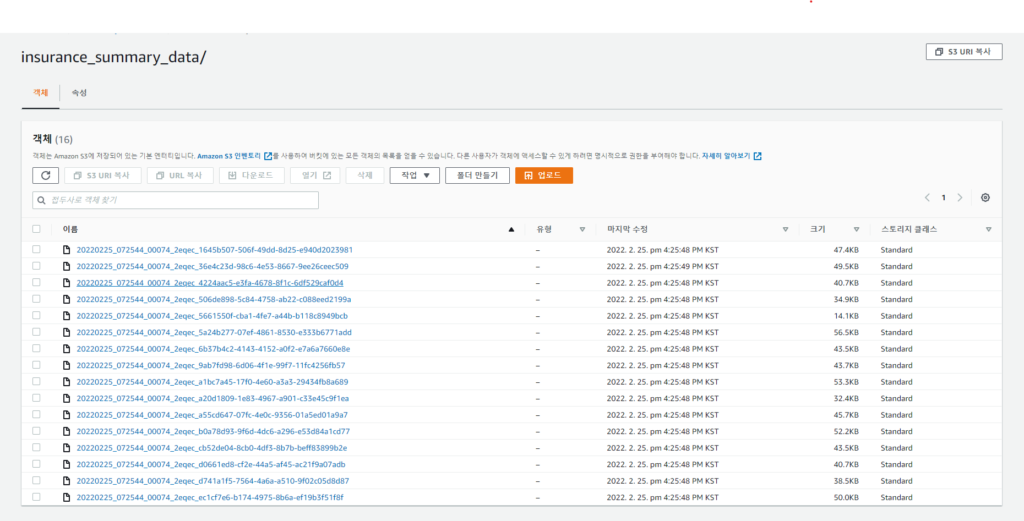
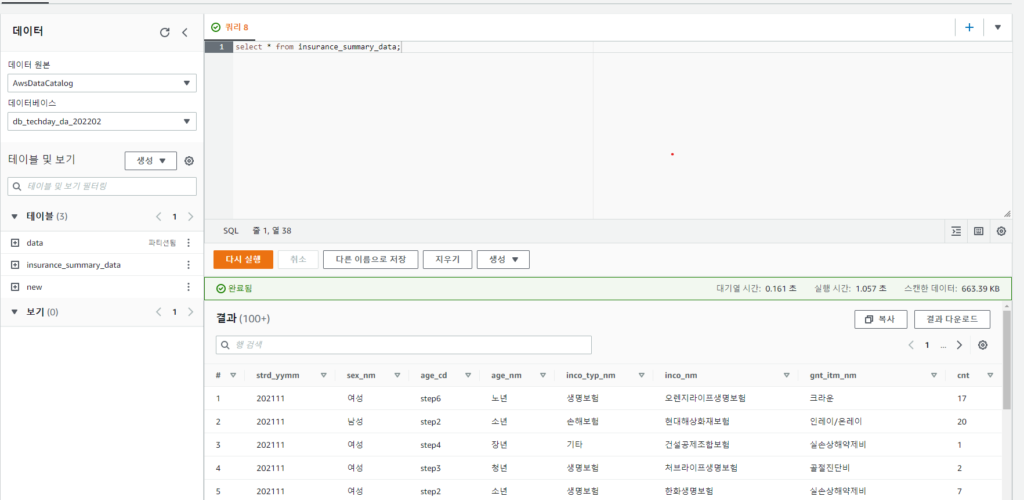
[Hands On]Athena로 공공데이터 분석하기Deployment Acceleration, 전체 / 글쓴이 이샘 사원 [AWS] Datalake DevOps <사전 준비> [Hands On] Glue를 통한 Csv to Parquet 파일 변환하기 위 링크된 페이지의 Glue 실습을 통해 생성된 공공데이터 Glue Catalog Table을 Athena로 분석해봅니다. Athena workgroup 작업 그룹을 사용하여 사용자, 팀, 애플리케이션 또는 워크로드를 구분하고, 각 쿼리 또는 전체 작업 그룹에서 처리할 수 있는 데이터 양의 한도를 설정하고, 비용을 추적할 수 있습니다.작업 그룹은 리소스 역할을 하기 때문에 리소스 수준 자격 증명 기반 정책을 사용하여 특정 작업 그룹에 대한 액세스를 제어할 수 있습니다.Amazon CloudWatch에서 쿼리 관련 지표를 볼 수 있고, 스캔된 데이터의 양에 대한 한도를 구성하여 비용을 통제할 수 있으며, 임계값을 생성하여 이러한 임계값이 위반될 경우 Amazon SNS와 같은 조치를 실행할 수 있습니다. < 생성방법> AWS Management Console에서 Amazon Athena > 작업그룹 메뉴 진입작업그룹 생성 버튼 클릭 쿼리 결과 위치 설정(S3 버킷의 폴더 생성하여 설정) Athena Editer 쿼리 편집기 메뉴 진입작업그룹을 위에 생성한 작업그룹으로 선택데이터 원본 선택(AwsDataCatalog) → 데이터베이스 선택→ 쿼리편집기 창에서 쿼리 수행 < SQL > 테스트 SQL Amazon Athena에 대한 SQL 참조 CTAS(CREATE TABLE AS)쿼리 select 쿼리문의 결과로 테이블을 생성할 수 있는 ctas 쿼리가 지원되어진다. ctas 쿼리문에서 지정한 s3위치에 데이터가 파일로 적재된다. CTAS로 생성된 테이블이 SQL문으로 정상적으로 조회되어진다.