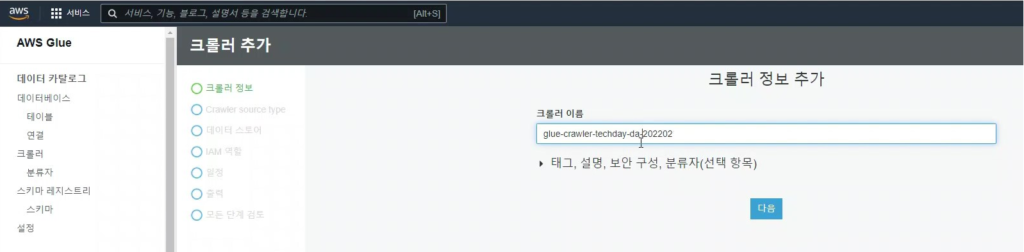
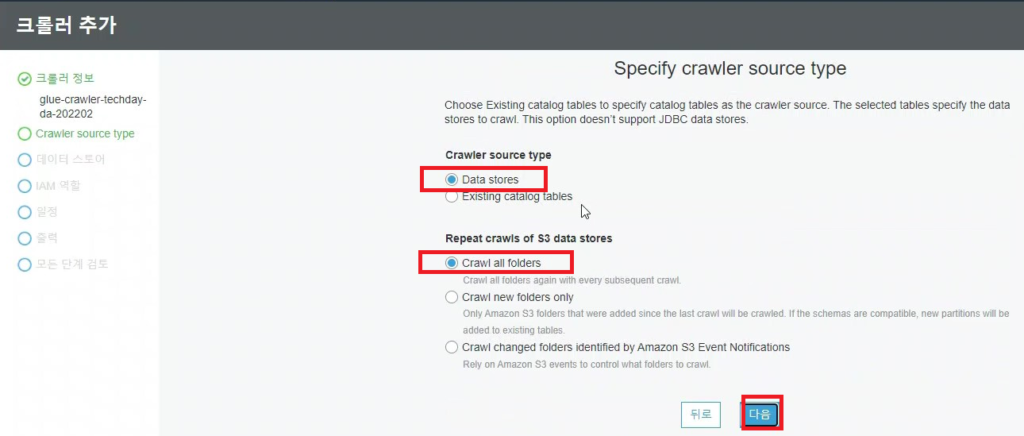
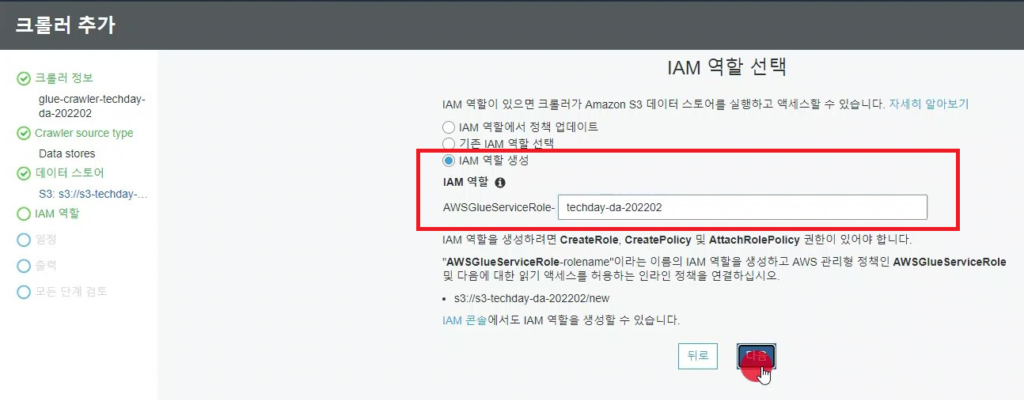
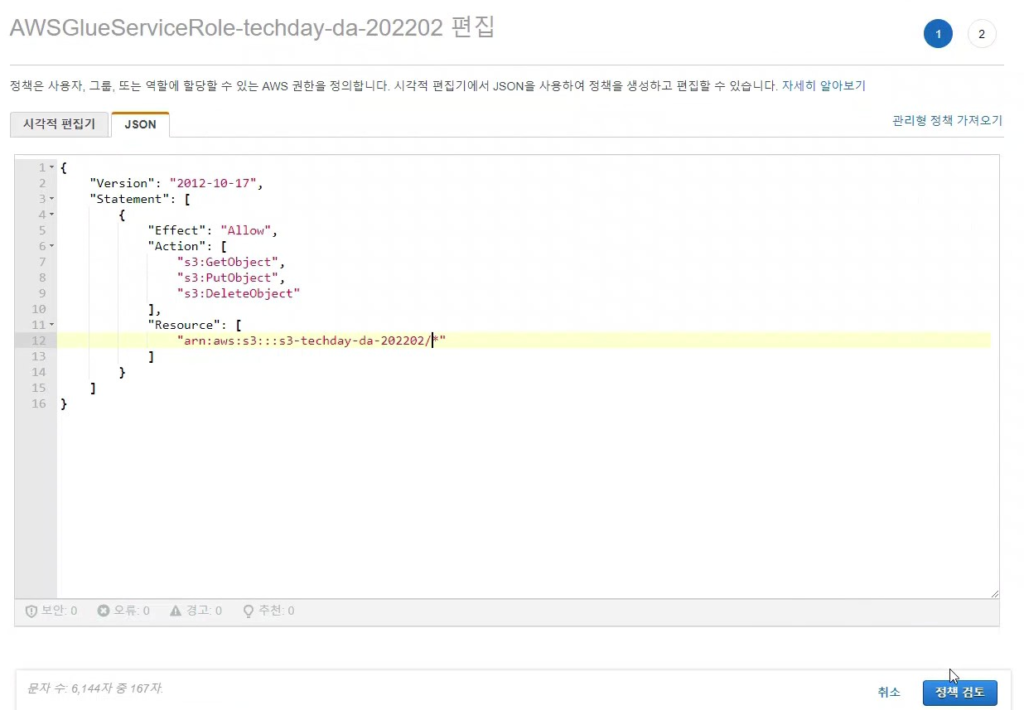
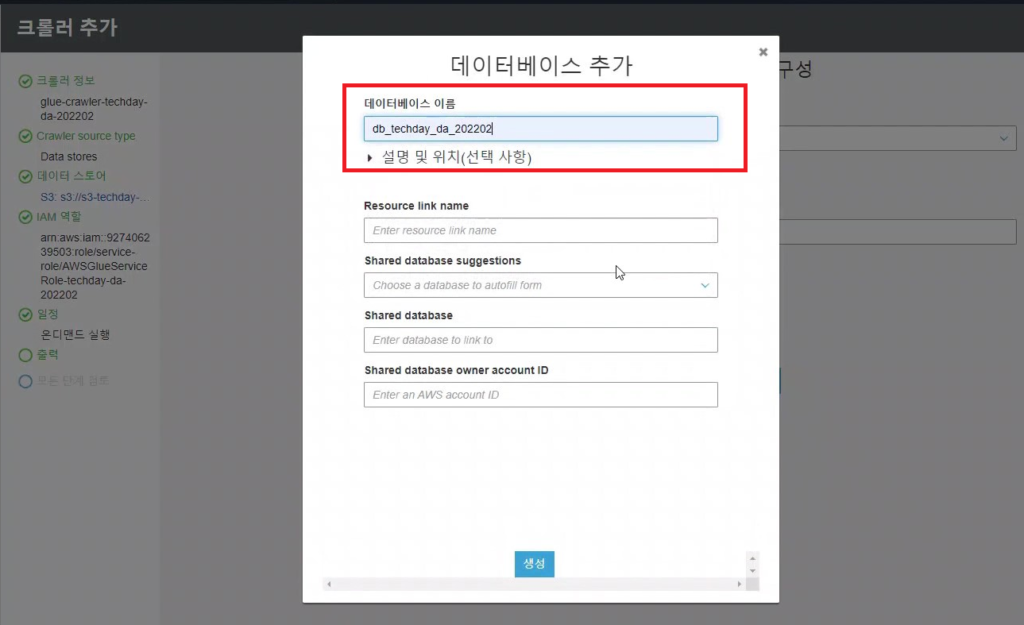
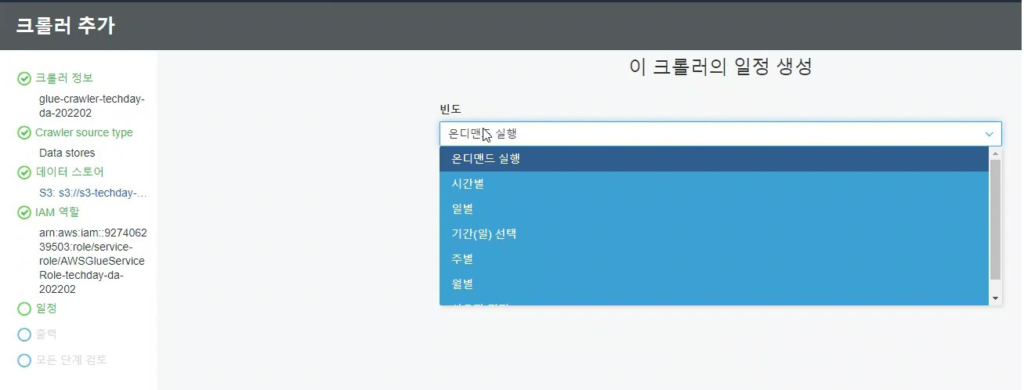
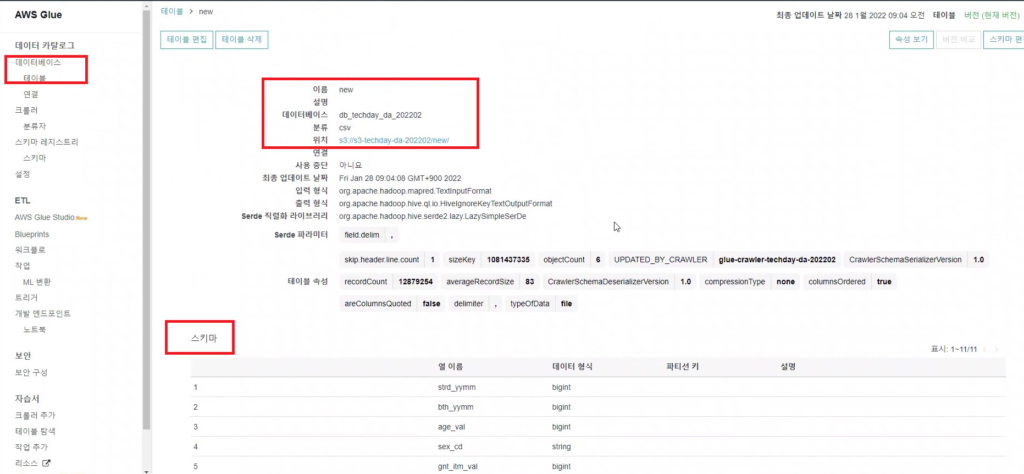
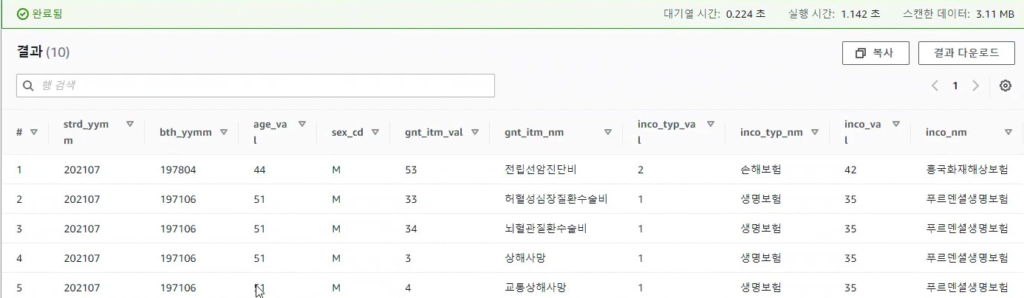
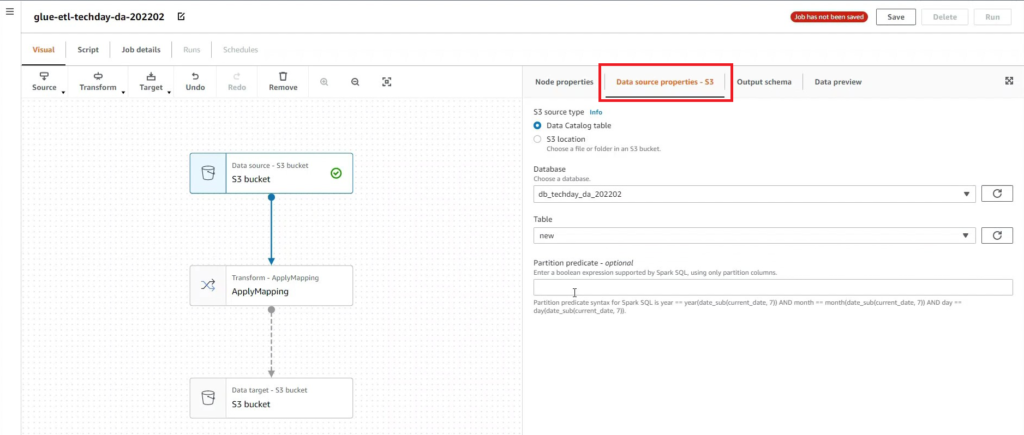
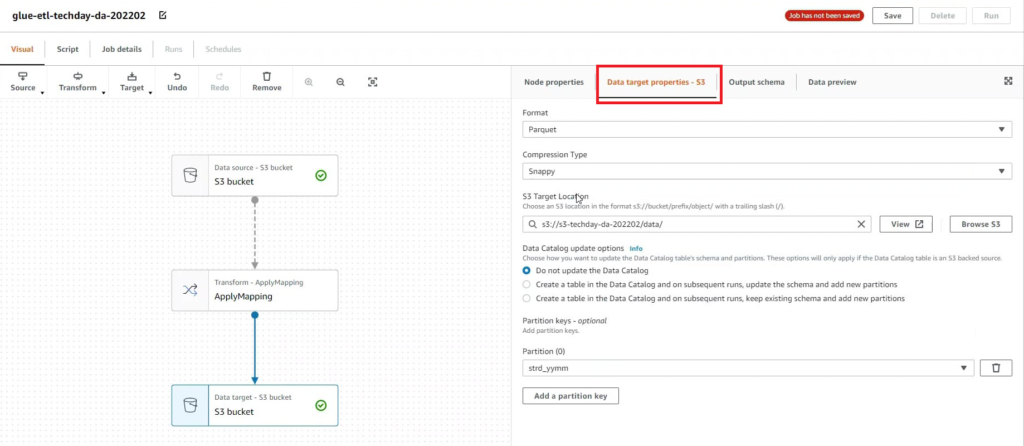
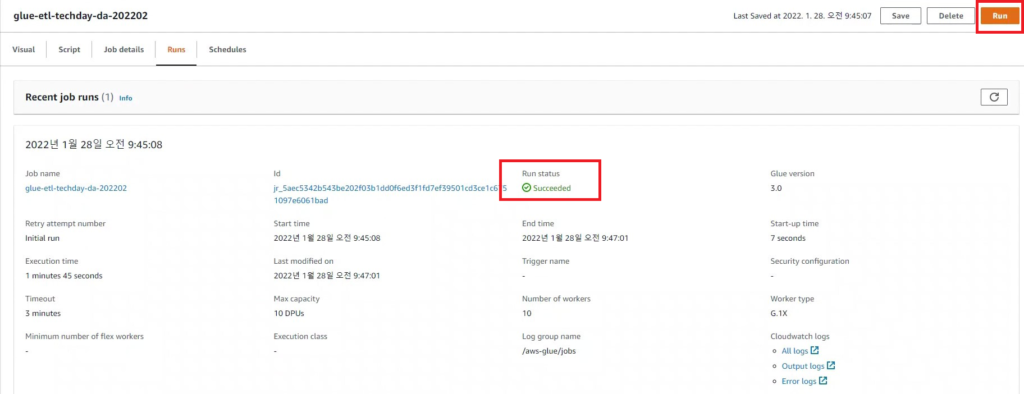
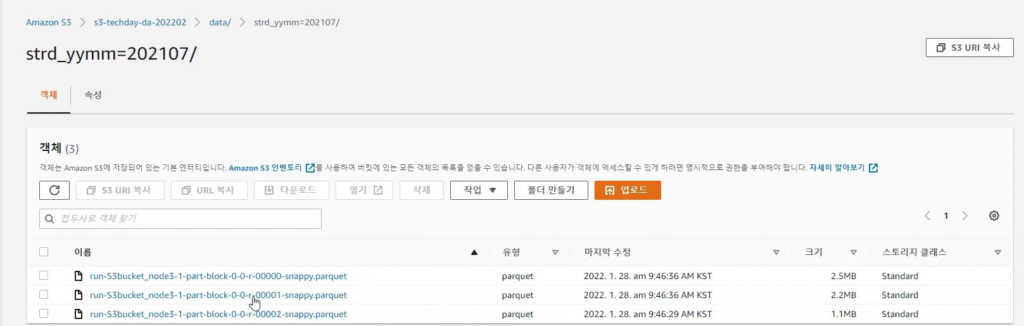
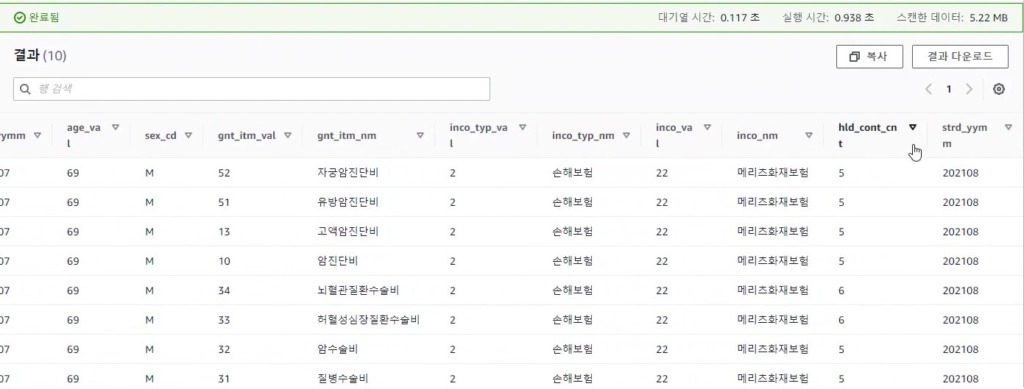
[Hands On]Glue를 통한 Csv to Parquet 파일 변환하기Deployment Acceleration, 전체 / 글쓴이 이샘 사원 [AWS] Datalake DevOps <사전 준비> [Hands On]S3 트리거에 의한 Lambda의 압축 파일 처리 위 링크된 페이지의 Lambda 실습을 통해 S3에 적재된 csv 파일에 대한 Parquet 변환 작업을 해봅니다. < Glue Crawler로 CSV 파일 스키마 생성> 크롤러를 사용하여 테이블로 AWS Glue Data Catalog를 채웁니다.ETL 작업은 원본 및 대상 Data Catalog 테이블에 지정된 데이터 스토어에서 읽기와 쓰기를 수행합니다. Aws Management Console에서 Aws Glue > Crawler 메뉴 진입 크롤러 추가 > 크롤러 이름 입력 Crawler Source Type는 “Data Stores” 선택 Repeat crawls of S3 data stores는 “Crawl all folders” 선택 > 다음 데이터 스토어 추가 > 데이터 스토어 선택은 “S3” > 다음위치의 데이터 크롤링은 “내 계정의 지정된 경로” 선택 > 포함경로는 Lambda실습시 csv가 업로드된 버킷의 폴더를 선택> 다른 데이터 스토어 추가는 “아니요” 선택 > 다음 IAM 역할 선택 > IAM 역할 생성 > 생성할 IAM 역할 이름 입력 > 다음 IAM 메뉴 > 역할 > 생성한 IAM 역할 조회 > 권한추가 > 인라인 정책 추가 > 정책검토 > 추가 크롤러의 출력 구성 > 데이터베이스 > 데이터베이스 추가 버튼 클릭 > 생성할 “데이터베이스 이름” 입력 > 생성 빈도(실행 주기 선택) > 온디맨드 실행 > 다음 구성옵션(선택사항) > “변경 사항을 무시하고 데이터 카탈로그에서 테이블 업데이트 안 함” 선택 (csv 원본 데이터의 변환오류로 인해 카탈로그 테이블의 역직렬화 라이브러리를 수동으로 변경해주기 때문에 크롤러로 스키마 생성시 해당 옵션 선택해 줌) > 다음 > 마침 크롤러 목록에서 생성해 준 크롤러 선택 > 크롤러 실행 > 테이블 추가됨 확인 AWS Glue > 데이터베이스 메뉴 진입크롤러 작업시 생성해 준 데이터베이스 선택 > 테이블 정보 확인 > 크롤링 된 테이블 스키마 확인 가능 주의! 이 상태로 Athena에서 조회해보면 원본 파일이 csv 파일인 이유로 기본 역직렬화 라이브러리인 org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe 로 인해 텍스트가 깨지고 숫자형식 컬럼이 정상적으로 조회되어지지 않는 현상 발생 AWS Glue > 데이터 카탈로그 > 데이터베이스 > 테이블(크롤링한 테이블명 선택)테이블 편집 버튼 클릭 > Serde직렬화라이브러리를 org.apache.hadoop.hive.serde2.OpenCSVSerde로 변경 > 적용 Athena에서 조회해 보면 정상적으로 보이는 것을 확인 가능하다 < Glue Studio로 Csv to Parquet ETL 작업 구성 > AWS Glue Studio 메뉴 진입 > View JobsCreate Job > Visual with a source and target 선택 > Source 는 Amazon S3 선택 > Target은 Amazon S3 선택 > Create 버튼 클릭 Source S3 버킷 아이콘 클릭 > Data Source Properties S3 설정 > S3 source type은 “Data Catalog table” 선택Database는 위에 생성해준 데이터베이스 선택 > Table은 위에 크롤링 해서 생성된 테이블명 선택 ApplyMapping단계에서 Souce Schema와 Target Schema의 매핑 컬럼정보를 설정 가능 Target S3 버킷 아이콘 클릭 > Data Source Properties S3 설정 Format은 “Parquet” 선택 Compression Type은 “Snappy” 선택 S3 Target Location은 생성되는 파일 업로드할 S3 버킷내 폴더 경로를 설정(source 버킷과 동일한 버킷에서 업로드 폴더만 새롭게 생성하여 테스트 진행함)Add a Partition Key 버튼 클릭 > “strd_yymm” 컬럼 선택(추후 분석시 성능에 영향을 미칠 수 있는 컬럼을 판단하여 파티션 키로 생성하는 것을 권장) Job Details 선택 > IAM Role은 크롤러 테스트시 생성한 IAM Role로 선택(Target S3 버킷을 새로 생성해준 경우 그에 맞는 정책 추가) Number of retries은 “0” 입력 Job timeout (minutes)은 “5” 입력Script path, Spark UI logs path, Temporary path 은 자신이 생성한 버킷의 폴더들을 생성하여 선택(테스트 후 자원 삭제등의 편의를 위해)Save 버튼 클릭 > Run 버튼 클릭 AWS Glue Studio 화면 상단 메뉴의 Run Details 선택 > Run 실행되고 있는 상태 및 결과 확인 가능 < Glue ETL 결과 S3 확인 > S3 메뉴 진입Glue ETL 작업시 Target 대상 S3 버킷의 폴더로 진입파티셔닝 된 폴더들이 생성되었는지 확인 ETL 작업으로 생성된 snnapy.parquet 파일 확인가능 < Glue Crawler로 Parquet 파일 스키마 생성> Aws Glue > Crawler 메뉴 진입크롤러 추가 > 크롤러 이름 입력 > 다음Crawler Source Type는 “Data Stores” 선택 > Repeat crawls of S3 data stores는 “Crawl all folders” 선택 데이터 스토어 추가 > 데이터 스토어 선택은 “S3” 다음위치의 데이터 크롤링은 “내 계정의 지정된 경로” 선택 > 포함경로는 ETL작업으로 인해 parquet 파일이 업로드 된 버킷내 폴더를 선택IAM 역할 선택 > IAM 역할 생성 > 기존 IAM 역할 선택 > 위에서 생성해준 IAM 역할 선택 > 다음 빈도(실행 주기 선택) > 온디맨드 실행 > 다음 크롤러 목록에서 생성해 준 크롤러 선택 > 크롤러 실행 > 테이블 추가됨 확인 AWS Glue > 데이터베이스 메뉴 진입크롤러 작업시 생성해 준 데이터베이스 선택 > 테이블 정보 확인 크롤링 된 테이블 스키마 확인 가능 Athena에서 정상 조회됨 확인